kube-prometheus-stack 监控etcd¶
默认部署好 kube-prometheus-stack ,如果Kubernetes集群采用了外部 etcd - 分布式kv存储 (例如: 部署TLS认证的etcd集群 ),那么 Grafana通用可视分析平台 中显示 etcd - 分布式kv存储 的内容是空白的。此时需要定制 values 并通过 更新Kubernetes集群的Prometheus配置 提交etcd相关配置(包括证书),这样才能对 etcd 完整监控。
通过 kube-prometheus-stack.values 配置 etcd 访问密钥¶
对于外部 etcd - 分布式kv存储 ,在 kube-prometheus-stack.values 有一段 kubeEtcd 配置,修订如下:
kube-prometheus-stack.values 配置监控外部 etcd ,使用etcd客户端证书访问(类似apiserver)¶## Component scraping etcd
##
kubeEtcd:
enabled: true
## If your etcd is not deployed as a pod, specify IPs it can be found on
##
endpoints:
- 192.168.6.204
- 192.168.6.205
- 192.168.6.206
## Etcd service. If using kubeEtcd.endpoints only the port and targetPort are used
##
service:
enabled: true
port: 2379
targetPort: 2379
# selector:
# component: etcd
## Configure secure access to the etcd cluster by loading a secret into prometheus and
## specifying security configuration below. For example, with a secret named etcd-client-cert
##
serviceMonitor:
scheme: https
insecureSkipVerify: false
serverName: localhost
#caFile: /etc/prometheus/secrets/etcd-client-cert/etcd-ca
#certFile: /etc/prometheus/secrets/etcd-client-cert/etcd-client
#keyFile: /etc/prometheus/secrets/etcd-client-cert/etcd-client-key
caFile: /etc/kubernetes/pki/etcd/ca.crt
certFile: /etc/kubernetes/pki/apiserver-etcd-client.crt
keyFile: /etc/kubernetes/pki/apiserver-etcd-client.key
##
serviceMonitor:
enabled: true
## Scrape interval. If not set, the Prometheus default scrape interval is used.
##
interval: ""
...
这里访问 etcd 证书我使用了管控服务器上的访问 etcd 证书
执行更新:
helm upgrade prometheus-community/kube-prometheus-stack¶helm upgrade kube-prometheus-stack-1681228346 prometheus-community/kube-prometheus-stack \
--namespace prometheus --values kube-prometheus-stack.values
这里我遇到一个报错:
helm upgrade prometheus-community/kube-prometheus-stack提示etcd相关错误¶rror: UPGRADE FAILED: rendered manifests contain a resource that already exists.
Unable to continue with update: Endpoints "kube-prometheus-stack-1680-kube-etcd" in namespace "kube-system" exists and cannot be imported into the current release: invalid ownership metadata;
annotation validation error: missing key "meta.helm.sh/release-name": must be set to "kube-prometheus-stack-1680871060";
annotation validation error: missing key "meta.helm.sh/release-namespace": must be set to "prometheus"
检查
endpoints:
kube-system namespace中的 endpoints (ep)¶kubectl -n kube-system get ep
输出显示 kube-etcd 和 kube-proxy 这两个 endpoints 是空的: kube-proxy 为空是因为我部署 Cilium完全取代kube-proxy运行Kubernetes
kube-system namespace中的 endpoints (ep) 输出¶NAME ENDPOINTS AGE
cilium-agent 192.168.6.101:9964,192.168.6.102:9964,192.168.6.103:9964 + 5 more... 240d
hubble-metrics 192.168.6.101:9965,192.168.6.102:9965,192.168.6.103:9965 + 5 more... 240d
hubble-peer 192.168.6.101:4244,192.168.6.102:4244,192.168.6.103:4244 + 5 more... 273d
hubble-relay 10.0.4.248:4245 245d
hubble-ui 10.0.3.238:8081 245d
kube-dns 10.0.0.137:53,10.0.1.71:53,10.0.0.137:53 + 3 more... 275d
kube-prometheus-stack-1680-coredns 10.0.0.137:9153,10.0.1.71:9153 11d
kube-prometheus-stack-1680-kube-controller-manager 192.168.6.101:10257,192.168.6.102:10257,192.168.6.103:10257 11d
kube-prometheus-stack-1680-kube-etcd <none> 11d
kube-prometheus-stack-1680-kube-proxy <none> 11d
kube-prometheus-stack-1680-kube-scheduler 192.168.6.101:10259,192.168.6.102:10259,192.168.6.103:10259 11d
kube-prometheus-stack-1680-kubelet 192.168.6.101:10250,192.168.6.102:10250,192.168.6.103:10250 + 21 more... 11d
otelcol-hubble-collector 10.0.3.173:4244,10.0.4.14:4244,10.0.5.89:4244 + 7 more... 235d
otelcol-hubble-collector-headless 10.0.3.173:4244,10.0.4.14:4244,10.0.5.89:4244 + 7 more... 235d
otelcol-hubble-collector-monitoring 10.0.3.173:8888,10.0.4.14:8888,10.0.5.89:8888 + 2 more... 235d
备份并删除 kube-prometheus-stack-1680-kube-etcd
kubectl -n kube-system get ep kube-prometheus-stack-1680-kube-etcd -o yaml > ep_kube-prometheus-stack-1680-kube-etcd.yaml
kubectl -n kube-system delete ep kube-prometheus-stack-1680-kube-etcd
但是报错依旧一摸一样: 我发现原来刚删除掉 ep 立即自动生成。
感觉是之前部署的时候默认激活了 etcd 监控导致添加了 ep ,而且这个 ep 是自动刷新的。推测可以先关闭掉 etcd 监控,使得这个 kube-system namespace中 ep 消失,然后重新激活 etcd 监控配置:
修订
kube-prometheus-stack.values:
kube-prometheus-stack.values 配置暂时去除 etcd 监控¶ ## Component scraping etcd
##
kubeEtcd:
enabled: false
然后再执行依次更新:
kubeEtcd 配置(false),然后执行依次 helm upgrade 消除掉 kube-system namespace 中对应 etcd 的 ep¶helm upgrade kube-prometheus-stack-1681228346 prometheus-community/kube-prometheus-stack \
--namespace prometheus --values kube-prometheus-stack.values
完成后检查 endpoints :
kube-system namespace中的 endpoints (ep)¶kubectl -n kube-system get ep
可以看到 kube-prometheus-stack-1680-kube-etcd 项消失了
重新恢复
kube-prometheus-stack.values中kubeEtcd配置,注意这次我们需要将所有etcd监控配置项都填写好,然后执行helm upgrade就不再报错能够正常完成再次查看
endpoints:
kube-system namespace中的 endpoints (ep)¶kubectl -n kube-system get ep
可以看到现在 kube-prometheus-stack-1680-kube-etcd 对应已经加入了需要监控的服务器列表:
kube-system namespace中的 endpoints (ep)可以看到已经由 kube-prometheus-stack 加入了需要监控的etcd ep¶NAME ENDPOINTS AGE
cilium-agent 192.168.6.101:9964,192.168.6.102:9964,192.168.6.103:9964 + 5 more... 240d
hubble-metrics 192.168.6.101:9965,192.168.6.102:9965,192.168.6.103:9965 + 5 more... 240d
hubble-peer 192.168.6.101:4244,192.168.6.102:4244,192.168.6.103:4244 + 5 more... 273d
hubble-relay 10.0.4.248:4245 245d
hubble-ui 10.0.3.238:8081 245d
kube-dns 10.0.0.137:53,10.0.1.71:53,10.0.0.137:53 + 3 more... 275d
kube-prometheus-stack-1680-coredns 10.0.0.137:9153,10.0.1.71:9153 11d
kube-prometheus-stack-1680-kube-controller-manager 192.168.6.101:10257,192.168.6.102:10257,192.168.6.103:10257 11d
kube-prometheus-stack-1680-kube-etcd 192.168.6.204:2379,192.168.6.205:2379,192.168.6.206:2379 5m54s
kube-prometheus-stack-1680-kube-proxy <none> 11d
kube-prometheus-stack-1680-kube-scheduler 192.168.6.101:10259,192.168.6.102:10259,192.168.6.103:10259 11d
kube-prometheus-stack-1680-kubelet 192.168.6.101:10250,192.168.6.102:10250,192.168.6.103:10250 + 21 more... 11d
otelcol-hubble-collector 10.0.3.173:4244,10.0.4.14:4244,10.0.5.89:4244 + 7 more... 235d
otelcol-hubble-collector-headless 10.0.3.173:4244,10.0.4.14:4244,10.0.5.89:4244 + 7 more... 235d
otelcol-hubble-collector-monitoring 10.0.3.173:8888,10.0.4.14:8888,10.0.5.89:8888 + 2 more... 235d
但是,此时观察 prometheus 的WEB界面,可看到抓取没有成功:
Get "http://192.168.6.204:2379/metrics": read tcp 10.0.6.197:59238->192.168.6.204:2379: read: connection reset by peer
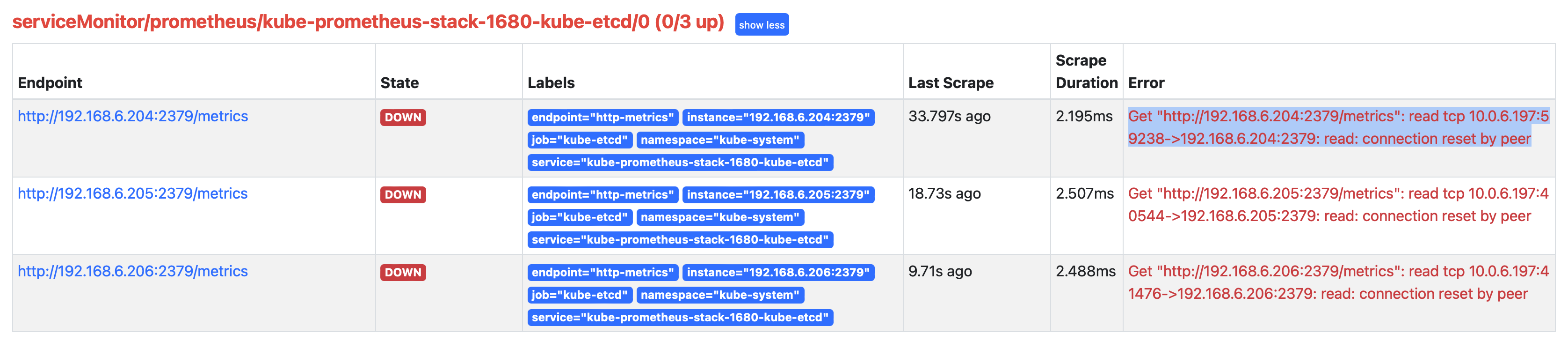
参考 Prometheus: Monitor External Etcd Cluster ,检查 prometheus
kubectl edit prometheus -n prometheus
发现确实没有对应的 secrets
secrets:
- <secret_name> # <--- Insert secret here 没有找到
检查
kubectl get servicemonitor -n prometheus可以看到:... kube-prometheus-stack-1680-kube-etcd 36m ...
仔细查看文档 Prometheus: Monitor External Etcd Cluster 发现了一个窍门, kube-prometheus-stack 约定了 <secret_name> 是存放密钥的路径中最后一段目录,例如:
caFile: /etc/prometheus/secrets/<secret_name>/ca.crt
certFile: /etc/prometheus/secrets/<secret_name>/apiserver-etcd-client.crt
keyFile: /etc/prometheus/secrets/<secret_name>/apiserver-etcd-client.key
所以,不能自己随便指定密钥目录
正确配置方法¶
重新配置
kube-prometheus-stack.values注意访问证书名字是有规律的:
kube-prometheus-stack.values 配置监控外部 etcd , 注意配置中的注释已经说明 证书名就是目录最后一段 etcd-client-cert¶## Component scraping etcd
##
kubeEtcd:
enabled: true
## If your etcd is not deployed as a pod, specify IPs it can be found on
##
endpoints:
- 192.168.6.204
- 192.168.6.205
- 192.168.6.206
## Etcd service. If using kubeEtcd.endpoints only the port and targetPort are used
##
service:
enabled: true
port: 2379
targetPort: 2379
# selector:
# component: etcd
## Configure secure access to the etcd cluster by loading a secret into prometheus and
## specifying security configuration below. For example, with a secret named etcd-client-cert
##
serviceMonitor:
scheme: https
insecureSkipVerify: false
#serverName: localhost
caFile: /etc/prometheus/secrets/etcd-client-cert/etcd-ca
certFile: /etc/prometheus/secrets/etcd-client-cert/etcd-client
keyFile: /etc/prometheus/secrets/etcd-client-cert/etcd-client-key
#caFile: /etc/kubernetes/pki/etcd/ca.crt
#certFile: /etc/kubernetes/pki/apiserver-etcd-client.crt
#keyFile: /etc/kubernetes/pki/apiserver-etcd-client.key
##
serviceMonitor:
enabled: true
## Scrape interval. If not set, the Prometheus default scrape interval is used.
##
interval: ""
...
## Deploy a Prometheus instance
##
prometheus:
enabled: true
...
## Settings affecting prometheusSpec
## ref: https://github.com/prometheus-operator/prometheus-operator/blob/main/Documentation/api.md#prometheusspec
##
prometheusSpec:
## If true, pass --storage.tsdb.max-block-duration=2h to prometheus. This is already done if using Thanos
##
disableCompaction: false
...
## Define which Nodes the Pods are scheduled on.
## ref: https://kubernetes.io/docs/user-guide/node-selection/
##
nodeSelector:
telemetry: prometheus
## Secrets is a list of Secrets in the same namespace as the Prometheus object, which shall be mounted into the Prometheus Pods.
## The Secrets are mounted into /etc/prometheus/secrets/. Secrets changes after initial creation of a Prometheus object are not
## reflected in the running Pods. To change the secrets mounted into the Prometheus Pods, the object must be deleted and recreated
## with the new list of secrets.
##
secrets:
- etcd-client-cert
...
备注
一定要配置 prometheus.prometheusSpec.secrets 添加 etcd-client-cert
按照
<secret_name>名字,将需要的证书都复制到当前目录下,准备好下一步创建secret:
mkdir etcd-client-cert
cd etcd-client-cert
sudo cp /etc/kubernetes/pki/etcd/ca.crt ./etcd-ca
sudo cp /etc/kubernetes/pki/apiserver-etcd-client.crt ./etcd-client
sudo cp /etc/kubernetes/pki/apiserver-etcd-client.key ./etcd-client-key
创建名为
etcd-client-cert的secret,这个etcd-client-cert必须对应于kube-prometheus-stack.values配置中存放证书目录的最后一段(代表secret名字):
etcd-client-cert 的 secret¶kubectl create secret generic etcd-client-cert -n prometheus --from-file=etcd-ca --from-file=etcd-client-key --from-file=etcd-client
完成后通过 kubectl get secret -n prometheus -o yaml 可以看到这个 etcd-client-cert 证书内容就是包含上述3个文件:
...
data:
etcd-ca: XXXXX
etcd-client: XXXXX
etcd-client-key: XXXX
执行更新:
helm upgrade kube-prometheus-stack-1681228346 prometheus-community/kube-prometheus-stack \
--namespace prometheus --values kube-prometheus-stack.values
更新以后检查 kubectl edit prometheus -n prometheus 可以看到 secret 已经加入:
...
secrets:
- etcd-client-cert
securityContext:
fsGroup: 2000
runAsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
...
并且登陆到 prometheus pod中检查,可以看到 /etc/prometheus/secrets/etcd-client-cert 目录下确实正确链接了对应的证书文件,和 kube-prometheus-stack.values 配置符合
发现还是错误:
Get "http://192.168.6.206:2379/metrics": read tcp 10.0.6.146:55926->192.168.6.206:2379: read: connection reset by peer
我突然发现,怎么是采用了 http:// 协议,不是应该是 https:// 么?
检查了 Prometheus 的 Configuration 发现了奇怪的 job 显示是 scheme: http :
scrap etcd时候使用了http而不是https¶- job_name: serviceMonitor/prometheus/kube-prometheus-stack-1680-kube-etcd/0
honor_timestamps: true
scrape_interval: 30s
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
authorization:
type: Bearer
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
follow_redirects: true
enable_http2: true
relabel_configs:
...
可能和 kubectl -n kube-system edit ep kube-prometheus-stack-1680-kube-etcd 有关(为何会在 kube-system):
subsets:
- addresses:
- ip: 192.168.6.204
- ip: 192.168.6.205
- ip: 192.168.6.206
ports:
- name: http-metrics
port: 2379
protocol: TCP
警告
暂时没有解决这个问题,我准备采用 2381 http端口 暂时绕过这个问题,后续再有机会再实践
使用secret访问etcd进行监控(记录参考)¶
备注
Prometheus: Monitor External Etcd Cluster 详细配置
这个方案其实和 kube-prometheus-stack 是同出一源,只不过做了手工直接编辑,但是为理清关系提供了帮助
Prometheus要通过TLS安全访问etcd需要一个
secret,使用以下命令为 prometheus 创建访问 etcd - 分布式kv存储 的secret:
kubectl -n prometheus create secret generic <secret_name> \
--from-file=/etc/kubernetes/pki/etcd/ca.crt \
--from-file=/etc/kubernetes/pki/apiserver-etcd-client.crt \
--from-file=/etc/kubernetes/pki/apiserver-etcd-client.key
输出 2381 http端口的metrics方法(记录参考)¶
备注
如果 etcd - 分布式kv存储 采用了 静态Pods 部署模式,可以参考本段方案。不过,我的实践目前还是采用独立 部署etcd ,生产上为了降低依赖,会采用 Docker Atlas 直接运行 etcd 。所以,目前我的实践采用上文为 kube-prometheus-stack 独立配置 etcd 访问证书方式
Prometheus: installing kube-prometheus-stack on a kubeadm cluster (解决 Prometheus访问监控对象metrics连接被拒绝 的参考文档 )提供了另外一种解决方案:
为
etcd添加一个不加密的http访问 Metrics 端口2381# master where etcd is running master_ip=192.168.122.217 sed -i "s#--listen-metrics-urls=.*#--listen-metrics-urls=http://127.0.0.1:2381,http://$master_ip:2381#" /etc/kubernetes/manifests/etcd.yaml
这样 静态Pods 模式下会立即重启 etcd 服务并添加一个 2381 的 http 端口可以用来获取 Metrics
修订
kube-prometheus-stack.values,将默认2379(https)端口修订为2381kubeEtcd: enabled: true service: enabled: true port: 2381 targetPort: 2381
可能需要修订 Helm chat rules for etcd (具体请参考原文),视安装的
kube-prometheus-stack版本是否已经合并上游fixed patch:defaultRules: disabled: etcdHighNumberOfFailedGRPCRequests: true
参考¶
Prometheus Operator not scraping colocated etcd metrics 基于
kube-prometheus-stack的快速配置Prometheus Kube Etcd is showing down 0/1 提示了
prometheus.prometheusSpec.secrets添加etcd-client-certMonitoring External Etcd Cluster With Prometheus Operator 手工配置证书,可能行
How to monitoring external etcd cluster with tls + alert prometheusRule
Prometheus: Monitor External Etcd Cluster 这个网站提供了很多资料可以参考
Prometheus: installing kube-prometheus-stack on a kubeadm cluster