Kubernetes概览¶
什么是Kubernetes¶
Kubernetes是一个容器( Docker Atlas )调度管理系统,使得单机运行的容器能够在整个数据中心范围进行调度和运行。请把容器想象成一个进程,就如同单台主机中的进程能够在该主机的多处理器(SMP)上调度运行,如果将整个数据中心视为超级计算机,Kubernetes赋予了容器如同进程一样在成百上千的主机节点(类似单机的CPU核心)间调度运行。
Kubernetes抽象了数据中心的硬件基础设施,对外展示为一个巨大的资源池。这样部署和运行组件是,不用关注底层服务器。调度组件是由Kubernetes负责,并确保组件能够相互发现,互相通讯。
备注
如果从集群角度来看,Kubernetes确实具备了一定的操作系统能力:将每个Host主机视为一个网络CPU,则Kubernetes把整个数据中心组成了一台逻辑超级服务器,调度容器运行。
当然,还有存储、网络技术的组合,才能实现一个完整的网络操作系统。
如果说 docker ( Docker Atlas ) 使得开发人员不再关注软件运行环境,那么Kubernetes就进一步改进使得开发人员不再关注软件运行如何部署到数据中心。
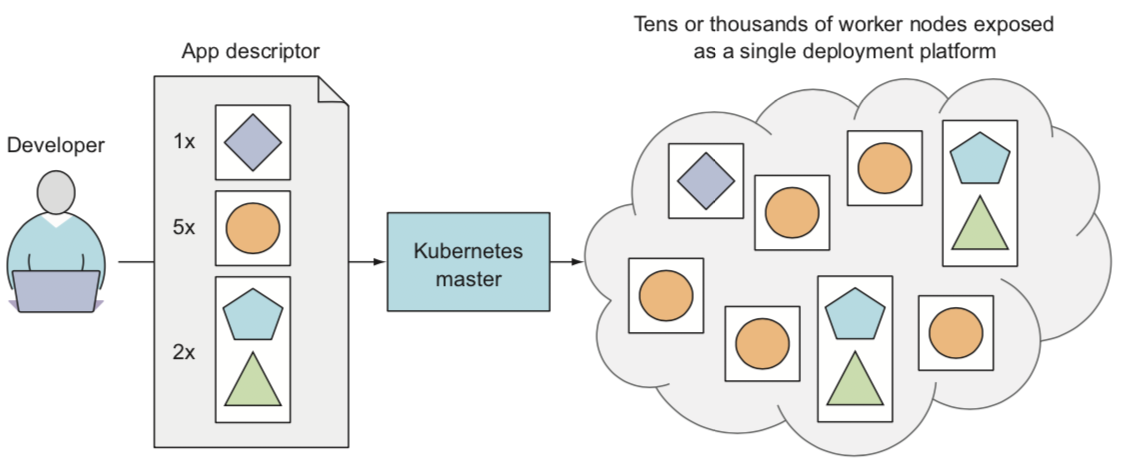
备注
开发人员只需要描述应用,就可以通过 Kubernetes master 将容器部署到数据中心到成百上千的服务器集群中。不论是开发人员还是运维人员,不需要关注容器具体运行在哪个服务器上,Kubernetes会负责完成容器的启动并保持运行,并在适当的时候销毁和重建容器。
Kubernetes将容器化的应用部署到集群中运行,并且提供了容器应用互相发现的标准化机制,这样无数的应用可以作为一个整体来运行。应用程序不需要关注其自身运行的节点,Kubernetes会随时调度应用到任意节点,混合不同的应用运行在数据中心的各个主机上,通过一定的性能检测和调度计算,使得数据中心的服务器资源充分发挥性能。
备注
现代应用开发趋势是将大型单体应用拆分成小型微服务,并且应用运行的基础架构转为容器化运行。
微服务组件以小型的可以独立部署的服务组件被部署到不同服务器上,并通过定义良好的接口(API)互相通讯协作。服务之间可以通过类似HTTP这样的同步协议,或者通过AMQP这样的异步协议通信。由于互相通信的协议标准化,所以微服务可以使用不同的语言进行开发。只要保证API不变或者向前兼容,就可以不断对微服务进行升级而不影响其他微服务或者不需要其他微服务重新部署。
微服务的另外一个优势是只需要扩容整个系统中负载增加的部分服务组件,从而节约计算资源。
但是,微服务也带来了复杂性:微服务需要以整体方式完成工作,所以需要正确配置所有微服务以使其能够作为一个单一系统进行正确工作。随着微服务数量不断增加,配置工作变得冗杂且易错。
此外,由于微服务跨多个进程和服务器,使得调试代码和定位异常调用变得困难,同时也带来了通讯开销。
备注
Kubernetes的分布式微服务架构带来软件异常排查调试非常困难, Jaeger分布式跟踪系统 和 Zipkin 是两种广泛使用的分布式跟踪系统,通过采集计时数据来排查延迟问题。
Kubernetes集群的架构¶
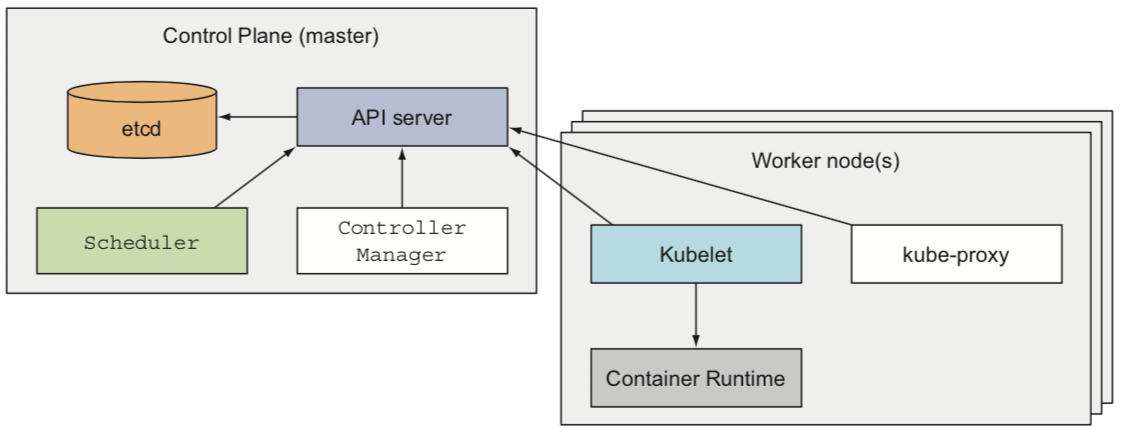
管控平台(Control Plane)¶
管控平台(Control Plane)是管控整个集群并使之工作的组成,包含了多个组件。这些组件可以运行在单一的master节点,也可以分散在多个节点并互相复制以确保高可用。管控平台的组件包括:
etcd : 一个可靠的分布式数据存储,用于持久化存户集群配置
etcd不仅是一个状态存储,也同时负责事件描述和leader选举。不同组件可以通过读写etcd中存储的状态来互相通讯以及顺序处理任务。例如组件leader选举,如调度器就是通过etcd来实现高可用,即只有一个scheduler是master处于工作状态,其他scheduler都是standby状态。
Kubernetes API Server (API服务): 交互所访问或者其他管控平台通讯的中心
虽然etcd是整个系统的核心(存储),但是所有组件相互通讯并不是直接访问etcd,而是通过一个代理,这个代理包装了etcd接口对外表现为一个标准的RESTFul API。此外,这个代理还实现了一些附加功能,例如认证,缓存等。这个代理就是 API Server
Controller Manager (控制管理器): 执行集群级别的功能,例如复制组件,跟踪工作节点,处理节点失效等等
Controller Manager是实现任务的调度(implementing the scheduling of a task)。总之一句话,所有直接请求Kubernetes要求调度的都是任务(task),例如Deployment, Daemon Set 或者 Job。每个任务请求被发送给Kubernetes之后,都是由Controller Manager处理的。每个任务类型都由一个Controller Manager负责。例如,一个Deployment则由Deployment Controller负责,而一个DaemonSet则由一个DaemonSet Controller负责。
Scheduler (调度器): 调度应用到不同工作节点
调度器是负责资源调度(resource scheduling)。当Controler Manager将资源请求写入到etcd,例如启动pod,此时调度器监视到需要调度一个新的Pod,就立即根据整个集群的状态来分配相应的节点来指派给这个Pod。
管控平台的组件负责获取和控制集群的状态,但不会用于运行应用程序。应用程序(的容器)由worker节点负责。
节点(nodes)¶
worker节点是运行容器化应用程序的服务器。负责运行、监控和向应用程序提供服务的任务由以下组件负责:
docker、rkt或者其他容器运行环境,负责运行容器
kubelet 负责和API服务器通讯以及管理各自节点上的容器
在每个worker node上都运行了一个kubelet代理:kubelet监视ETCD中的Pod信息,并在节点上运行相应的Pod,以及当Pod被指定到该节点运行后更新ETCD中的状态信息。
kube-proxy (Kubernetes Service Proxy) 负责在不同的应用组件负载均衡网络流量
Vanilla Kubernetes¶
Vanilla(香草) Kubernetes也称为开源Kubernetes,这是指最基本的Kubernetes,只包含最基本的Kubernetes组件:
api服务器
scheduler调度器
controller-manager控制管理器
kubelet 和 kube-proxy
容器运行时(例如Docker)
虽然开源Kubernetes(Vanilla Kubernetes)可以让用户完全控制自己的Kubernetes,但是由于Kubernetes主干组件提供的功能太基本了,实际上要满足业务需求还需要部署很多复杂的组件,如负载均衡,自动缩放,CI/CD,以及处理日志记录、监控和报警等,才能满足生产要求。
Kubernetes的复杂性使得很多中小型公司无法驾驭(自行部署和维护),所以产生了云厂商托管的Kubernetes,也就是Managed Kubernetes。
Kubernetes工作流程¶
以下举例创建Nginx的Pod过程:
Kubectl命令行,发出一个包含Ngninx创建的Deployment对象,kubectl将调用API Server,将这个Deployment对象写入到ETCD
Deployment Controller监视到ETCD中有一个新的Deployment对象已经创建,就会获取这个对象信息。接下来Deployment Controller指挥任务调度到相应到对象信息,然后创建一个正确的Replica Set对象
Replica Set Controller监视到一个新的对象创建了,就会读取对象信息来完成任务调度并创建相应的Pod
调度器Scheduler监视到新的Pod已经创建,就会读取这个Pod的对象信息,将这个Pod调度到基于集群状态分配的一系列节点,然后更新Pod(也就是将Pod绑定到Node上)
Kubelet监视到对应节点的新Pod,就根据对象信息运行Pod,并回写更新ETCD中Pod状态
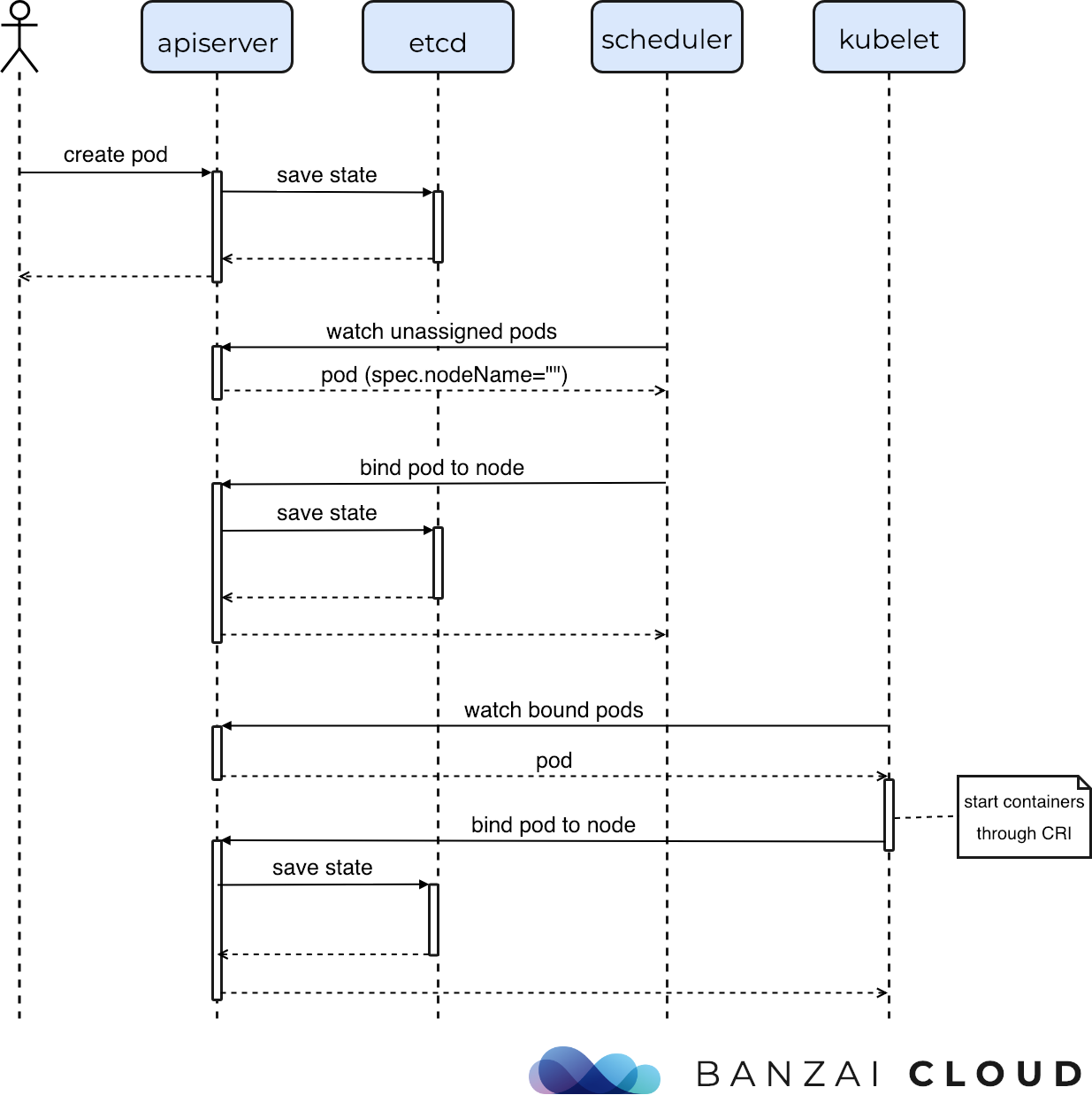
时序图参考 BANZA CLOUD Writing custom Kubernetes schedulers¶
在Kubernetes中运行应用¶
要在Kubernetes中运行一个应用程序,首先需要将应用程序打包到一个或多个容器镜像,将镜像推送到镜像中心(image registry),然后通过提交一个应用到描述给Kubernetes API服务器来实现。
这个描述信息包括诸如容器镜像或包含应用组件的镜像,组件互相之间的关系,组件之间的依赖(例如需要需要运行在同一个节点或者不能运行在同一个节点)。对于每个组件,也可以指定副本数量(或 replicas )。此外,描述也可以包括这些组件提供给内部或外部客户的服务,以及如何通过一个单一IP地址输出,或者组件对于其他组件如何能够被发现。
描述对于运行的容器的作用¶
当API服务器处理应用的描述,则调度器(seheduler)会基于每个组请求的计算资源编排指定组的容器到可用的工作节点,并且释放需要的资源。每个节点上的Kubelet就会命令容器运行环境(例如Docker)去下载需要的容器镜像,然后运行容器。
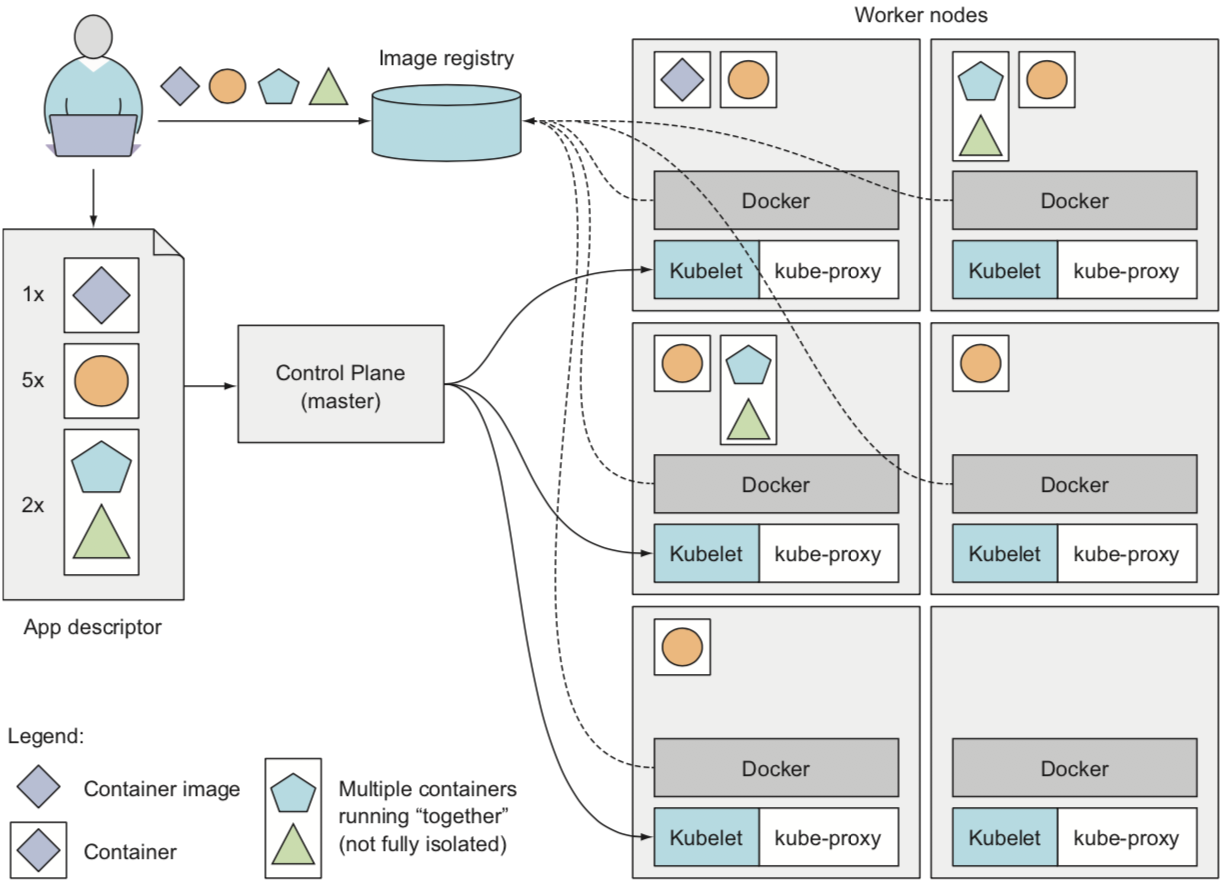
上述示意图中,app descriptor(应用描述)列出了4个容器,划分为3个集合(set),这些集合在Kubernetes中称为 pods 。前两个pods每个只包含一个单一容器,而最后一个pod则包含了2个容器(这意味着这两个容器必须一起运行相互不能隔离)。每个pod在描述中还包括了副本数量,也就是需要并行运行的同一个pod的副本数量。
当描述发送给Kubernetes,Kubernetes就会调度每个pod的指定数量副本部署到可用的工作节点。在集群节点上运行的Kubelet服务则会调用Docker来下载容器镜像并运行容器。
保持容器始终运行¶
一旦应用开始运行,Kubernetes会一直确保应用的部署状态和你提供的描述相一致。例如,如果你指定希望web服务器保持5个实例,则Kubernetes就会确保有5个实例运行。如果某个实例停止意外停止,例如crash或者停止响应,Kubernetes会自动重启该容器。类似,如果整个worker节点都死掉或者不可访问,Kubernetes将为所有运行在该节点上的容器选择新的节点来运行。
运行副本的伸缩性¶
当应用运行时,可以决定增加或缩减运行副本数量,Kubernetes会相应增加或停止副本。这个伸缩操作可以基于实时监控,例如CPU负载,内存消耗,每秒的查询量以及其他指定的应用监控项。
稳定的服务访问入口¶
由于Kubernetes可能会在集群中不断调度容器实例,所以需要Kubernetes对外输出稳定的服务,例如固定的IP地址并将地址输出给运行在集群中的其他应用。这可以通过环境变量,或者DNS解析。Kube-proxy可以确保服务被负载均衡分发到所有提供这个服务的容器上,这样的对外输出IP地址是不变的,以便客户端能够稳定连接。
Kubernetes的优势¶
简化应用部署¶
Kubernetes将所有的工作节点输出成一个单一的部署平台,应用程序开发者可以自行启动部署应用而不需要了解集群中服务器如何部署应用。
Kubernetes通过标签分类使得集群底层的服务器能够按照不同的共性进行分组抽象,使得部署只需要按照分组就可以找到合适的资源。
充分发挥硬件能力¶
Kubernetes能够基于应用程序的资源描述以及节点的可用资源,自动编排应用程序到最合适的节点运行应用。这个过程是自动完成,所以不需要开发者或部署者人工干预。由于避免了人工在繁杂的资源类型中排列组合,Kubernetes通过自动优化组合实现了应用的最佳部署。
健康检查和自愈¶
Kubernetes监控应用组件以及运行的节点,在节点故障时可以自动重排应用运行节点。这种自动修复的能力使得系统管理员无需手工迁移应用,在资源充足的情况下,完全可以让系统自动修复,并在合适的时候集中人工处理。
自动伸缩性¶
通过监控应用负载,Kubernetes提供了自动伸缩应用程序的运行实例数量,可以基于监控资源的使用自动调整每个应用的运行实例数量。
简化应用程序部署¶
Kubernetes内置了通过Kubernetes API方式获取应用环境以及依赖关系,这样应用部署可以简化。应用服务器可以查询Kubernetes API服务器获取环境变量或执行DNS查询。