HPE服务器监控¶
我在自己的 HPE ProLiant DL360 Gen9服务器 服务器上构建硬件监控,基于 Grafana通用可视分析平台 来观察:
硬件是否工作正常,例如内存模块、风扇、主板等
监控服务器温度,特别是处理器和GPU以及磁盘
HPE公司提供了一个
处理器¶
Intel 和 AMD 都开发了针对自家处理器的性能监控调试工具:
如果要采用通用型监控处理器温度,则可以采用 lm_sensors(Linux监控传感器)
基于 pcm-exporter :Intel Performance Counter Monitor (Intel PCM) Prometheus exporter¶
采用 Intel® Performance Counter Monitor (Intel® PCM) 官方提供的 pcm-exporter :Intel Performance Counter Monitor (Intel PCM) Prometheus exporter 可以精细化监控Intel处理器(脑洞: 对于 KVM Atlas 虚拟化的处理器,能否模拟使用Intel PCM来监控?),直接输出 Grafana通用可视分析平台
基于 AMD SMI Prometheus Exporter¶
由于 AMD μProf 尚未支持 Metrics , 目前还不能基于uProf来构建AMD处理器的监控。不过,AMD开源了基于AMD SMI库输出为metrics的 AMD SMI Prometheus Exporter ,目前还没有完整方案,但可以尝试。
基于 HP服务器iLO技术¶
结合 Prometheus监控¶
HP服务器iLO技术 提供了大量的基础监控数据,有人开发了 HP iLO Metrics Exporter (GitHub) 可以直接将 HP服务器iLO技术 监控数据输出为 Metrics 。并且这个 Prometheus Exporters 被 greenweb-cloud prometheus_exporters (GitHub) (这个项目综合了很多开源的exporter)收录。对应于 HP iLO Metrics Exporter 有一个 Grafana通用可视分析平台 Dashboard HP iLo 可以观察硬件设备是否工作正常:
0 - OK
1 - Degraded
2 - Dead (Other)
结合 Influxdb时序数据库¶
Influxdb时序数据库 有一个更好的结合 HP服务器iLO技术 监控方案,对应的 Grafana通用可视分析平台 Dashboard案例:
可以看到社区提供的 InfluxDB 有丰富的iLo集成数据,可以精细化监控服务器的温度和主频。
基于 IPMI¶
Prometheus Exporters 有一个官方
ipmi_exporter可以基于 IPMI 输出 Metrics 。使用 Grafana通用可视分析平台 Dashboard IPMI ExporterNode Exporter with IPMI工具ipmitool text plugin 可以使用 Grafana通用可视分析平台 Dashboard IPMI for Prometheus
这样可以用来监控大规模服务器集群,并且生成告警。
基于 lm_sensors(Linux监控传感器)¶
sensor-exporter (GitHub) 基于 lm_sensors(Linux监控传感器) 提供了温度和风扇转速的 Metrics 输出。对应 Grafana Dashboard: Sensors 提供了监控案例
基于 HPE OneView¶
HPE OneView 是HPE官方开发的监控服务器硬件和电路连接模块的软件,提供了 REST API 来搜集信息: power consumption (average and peak), ambient temperature, CPU utilization 等。基于 HPE OneView 有一些第三方监控插件:
hpe-oneview-prometheus (GitHub) 输出可以被 Prometheus监控 采集的 Metrics ,并且有一个配套的 Grafana通用可视分析平台 Dashboard ID 10233 提供各个组件的状态监控:
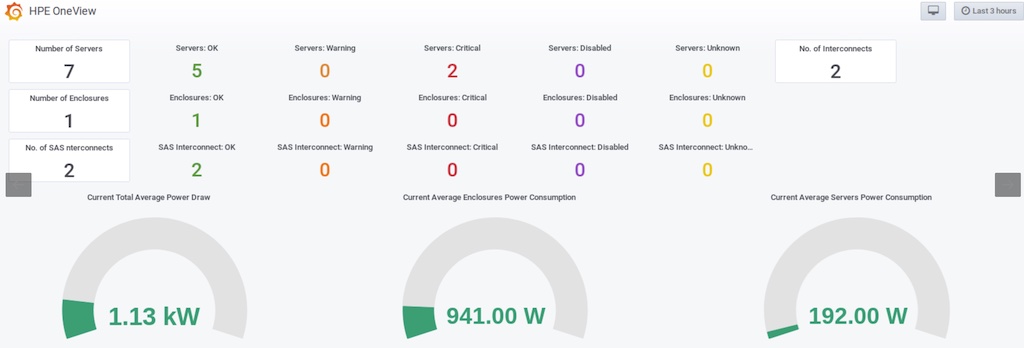
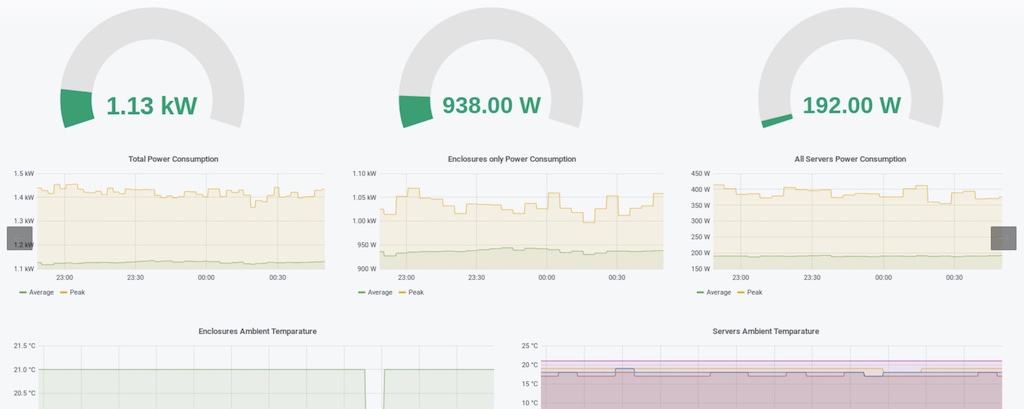
不过这个监控主要是布尔值,也就是主要判断设备是否工作正常。
HPE Storage Array Exporter¶
Get started with Prometheus and Grafana on Docker with HPE Storage Array Exporter 提供了采用官方 HPE Storage Array Exporter 实现 Prometheus监控 集成监控。这是一个企业级解决方案,适合集成到 Kubernetes 监控系统。
不过,我没有 HPE Storage Array 硬件设备,这里仅记录备用。
Integration of HPE OneView with Prometheus 是HPE提供的集成到 OpenShift Atlas 部署方案,也可以参考。
备注
根据资料对比,我准备实现:
采用 Prometheus监控 结合
ipmi_exporter实现一个通用的服务器监控(适合任意服务器品牌)采用 Influxdb时序数据库 结合
iLo实现一个针对HP服务器的特定监控采用 lm_sensors(Linux监控传感器) 结合 sensor-exporter (GitHub) 尝试做一个简化版温度监控