VS Code插件Continue连接Ollama实现AI辅助编程
Continue 插件为 VS Code 提供了直接使用OpenAI作为AI编码后端的能力,同时也可以连接本地部署的大语言模型,实现完全自主控制的LLM大模型编程。
我在 Ollama使用AMD GPU运行大模型 验证运行了 Qwen2.5-coder 之后,尝试结合到 VS Code 进行AI编程:
Continue提供了 chat 模式对话,以及自动补全和代码自动注释等功能,使用方便,无需频繁切换终端
硬件环境和规划
2026年初,我剁手了两块 NVIDIA Tesla A2 GPU运算卡 ,此外在2025年剁手的 AMD Radeon Instinct MI50 以及更早的 Nvidia Tesla P10 GPU运算卡 ,形成了混合架构的GPU硬件。由于 NVIDIA Tesla A2 GPU运算卡 功耗极低,我准备在淘宝上购买涡轮静音风扇组装到我的台式机上,实现7x24小时持续运行的推理平台。另外也改造了 Nvidia Tesla P10 GPU运算卡 增加了显卡散热风扇,一并安装到台式机上:
双 NVIDIA Tesla A2 GPU运算卡 合计有32GB显存,Ampere架构,具备了第二代 Tensor Core,比 Nvidia Tesla P10 GPU运算卡 先进了两个代际
Nvidia Tesla P10 GPU运算卡 24GB显存,Pascal架构,没有Tensor Core
规划通过安装 NVIDIA Container Toolkit 构建2个不同的容器构建"双引擎"AI工作站:
qwen2.5-coder:32b-instruct-q4_K_M需要20GB显存,对于双 NVIDIA Tesla A2 GPU运算卡 (合计32GB)还能有12GB显存用于KV cache的上下文,支持约 16,384 到 24,576 tokens 的上下文长度(取决于是否开启了 GQA 优化),这样对于代码逻辑和架构设计会非常均衡负载均衡:Ollama 会自动将模型的 64 层(Layers)平均分配到两块 A2 上,每块卡负担约 32 层。这样每块卡的显存占用都在 14GB - 15GB 左右,处于非常健康的区间
算力对齐:两块A2卡并行的总核心数(CUDA Cores)能让 32B 模型的推理速度维持在 10 - 15 tokens/s 左右。对于代码生成来说,这已经非常流畅(每秒能写 20-30 行代码)。
Nvidia Tesla P10 GPU运算卡 相对性能较弱,不过内存有24GB是一个优势,考虑后续尝试作为项目代码分析(可能会比较慢)
安装和配置
在 VS Code中选择插件市场,搜索 continue 并安装
打开VS Code,按下
Ctrl+Shift+P,然后输入Continue: Open Settings这里有一个界面是登陆
Coninue Hub,不过也提供了另外一个选项是Or, configure your own models,我们就选择这个配置自己的模型选择本地运行模型
跳过导引,选择直接编辑配置,然后参考 Continue model providers 配置文件配置,我这里再次配置选择 Ollama使用AMD GPU运行大模型 实践过 Qwen2.5-coder ,就不需要重复下载新模型,而且也是目前我的硬件能够运行的最好的编码模型
备注
上述配置其实有点迷糊,可能需要摸索摸索。我自己也是按照导引做的,但是看起来continue的界面迭代变化块,和文档并不相同,所以我也就在这里不再记录了。
使用
Continue 提供了一个chat模式,就好像直接和Ollama对话
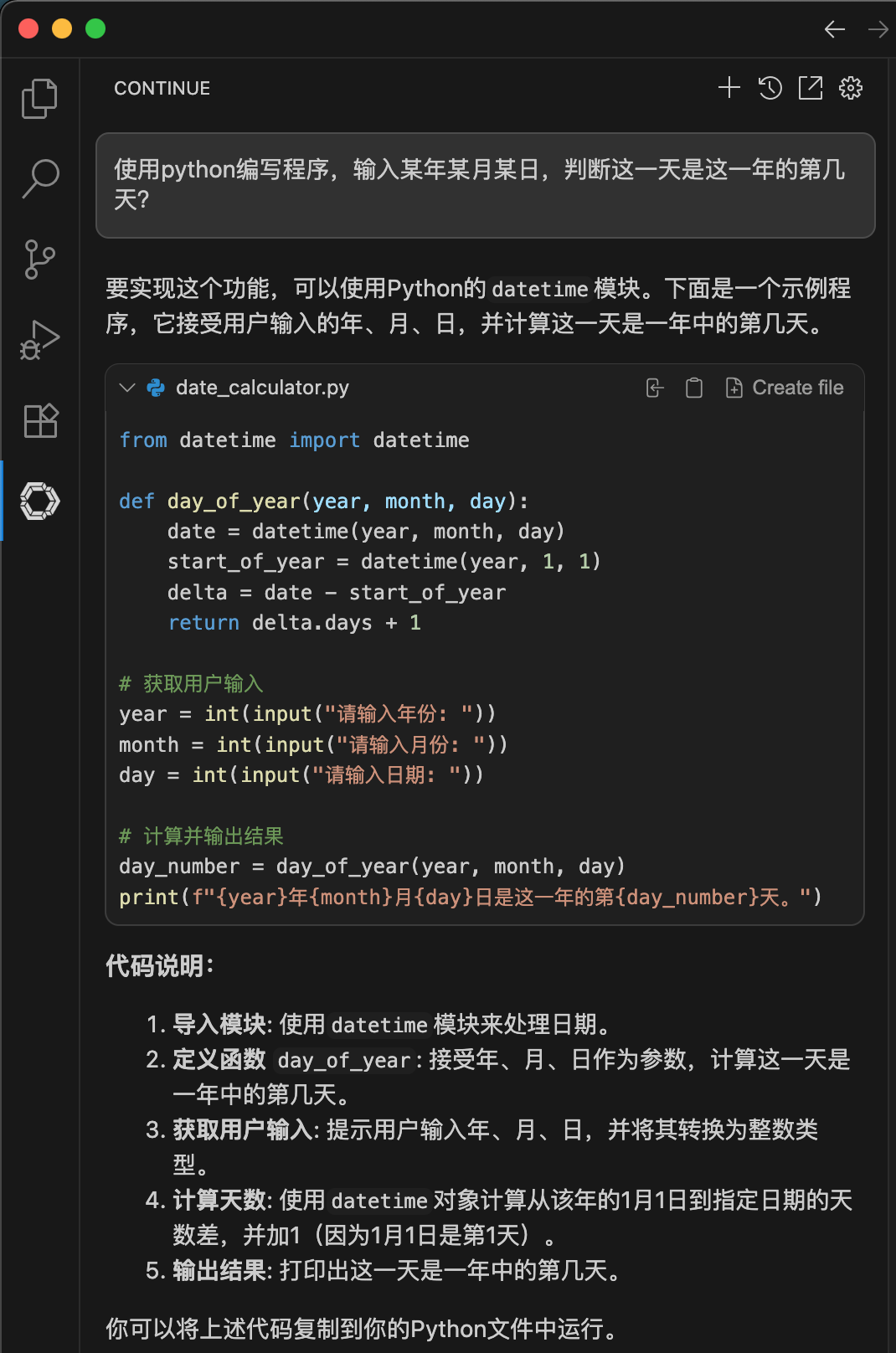
对话模式通过提示获取代码片段
其实使用chat模式就很方便,通过简单对话就能获取代码片段进行参考,也方便学习编程
代码注释比较有用,特别是看到一时无法理解的代码,让 continue 调用 Ollama 帮我解析,可以快速完成代码阅读
其他功能探索中...