在Docker中Ollama使用NVIDIA A2 GPU运行大模型
安装驱动
备注
在配置使用GPU之前,请先完成 GPU相关BIOS设置
安装NVIDIA Linux驱动(Ubuntu) : 在Host主机上仅安装NVIDIA驱动来支持安装 NVIDIA Container Toolkit ,这样就可以容器化运行 NVIDIA CUDA
ubuntu-drivers devices
根据输出显示选择合适的驱动,这里选择 590-server 版本
590-server 驱动apt install nvidia-driver-590-server
安装NVIDIA Container Toolkit
执行以下步骤完成 NVIDIA Container Toolkit 安装
sudo apt-get update && sudo apt-get install -y --no-install-recommends \
ca-certificates \
curl \
gnupg2
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
NVIDIA Container Toolkitexport NVIDIA_CONTAINER_TOOLKIT_VERSION=1.19.1-1
sudo apt-get install -y \
nvidia-container-toolkit=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
nvidia-container-toolkit-base=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
libnvidia-container-tools=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
libnvidia-container1=${NVIDIA_CONTAINER_TOOLKIT_VERSION}
安装Docker Engine(docker-ce) 并使用
nvidia-ctk命令来配置容器运行时
# Add Docker's official GPG key:
sudo apt update
sudo apt install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
# Add the repository to Apt sources:
sudo tee /etc/apt/sources.list.d/docker.sources <<EOF
Types: deb
URIs: https://download.docker.com/linux/ubuntu
Suites: $(. /etc/os-release && echo "${UBUNTU_CODENAME:-$VERSION_CODENAME}")
Components: stable
Signed-By: /etc/apt/keyrings/docker.asc
EOF
sudo apt update
sudo apt install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
docker 用户组sudo usermod -aG docker $USER
sudo nvidia-ctk runtime configure --runtime=docker
启动Ollama容器
备注
在中国,需要 越过长城 : 我采用 Docker 代理快速起步(Socks版本) 方法
执行以下命令启动Ollama容器以及辅助的监控和web容器
# 官方运行命令
# docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
# 创建ai-network网络用于连接不同容器
docker network create ai-network
# 创建存储数据目录
export data_dir=/home/admin/docker
mkdir -p $data_dir/{ollama_data,open-webui_data,prometheus_data,grafana_data}
# 优化参数运行ollama
docker run -d --gpus=all \
--network ai-network \
-v $data_dir/ollama_data:/root/.ollama \
-p 11434:11434 \
--name ollama \
-e OLLAMA_HOST=0.0.0.0 \
-e OLLAMA_FLASH_ATTENTION=1 \
-e OLLAMA_KEEP_ALIVE=24h \
--restart always \
ollama/ollama
# 运行open-webui
docker run -d \
--network ai-network \
-p 3000:8080 \
-v $data_dir/open-webui_data:/app/backend/data \
-e OLLAMA_BASE_URL=http://ollama:11434 \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
# 运行NVIDIA DCGM Exporter抓取显卡温度、显存、功耗等监控数据
# 具体版本号见 https://github.com/NVIDIA/dcgm-exporter
# 官方 nvcr.io 镜像需要注册登录非常麻烦,改为直接冲Docker Hub下载
# DCGM_EXPORTER_VERSION=4.5.2-4.8.1-distroless && \
docker run -d \
--gpus all \
--cap-add SYS_ADMIN \
-p 9400:9400 \
--network ai-network \
--name nvidia-exporter \
--restart always \
nvidia/dcgm-exporter:latest
#nvcr.io/nvidia/dcgm-exporter:$DCGM_EXPORTER_VERSION
# 可以在宿主机上验证是否监控数据抓取成功
curl http://localhost:9400/metrics | grep DCGM_FI_DEV_GPU_TEMP
# 创建prometheus.yml
cat <<EOF > /home/admin/docker/prometheus_data/prometheus.yml
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'gpu-metrics'
static_configs:
- targets: ['nvidia-exporter:9400']
- job_name: 'ollama'
static_configs:
- targets: ['ollama:11434']
EOF
# 运行Prometheus
docker run -d \
--network ai-network \
--name prometheus \
-p 9090:9090 \
-v $data_dir/prometheus_data:/etc/prometheus \
--restart always \
prom/prometheus
# 运行Grafana
docker run -d \
--network ai-network \
--name grafana \
-p 3001:3000 \
-v $data_dir/grafana_data:/var/lib/grafana \
-e "GF_SECURITY_ADMIN_PASSWORD=admin" \
--restart always \
grafana/grafana
备注
其中访问 nvcr.io 镜像仓库需要登录(我已放弃改为使用Docker Hub):
访问 NVIDIA NGC 并注册/登录
在右上角点击
你的头像 -> Setup -> Generate API Key在终端执行登录:
# 用户名固定为 $oauthtoken
docker login nvcr.io
# Username: $oauthtoken
# Password: <你的 API Key>
注意,Grafana建议导入dashboard:
最推荐: ID 15117 (NVIDIA DCGM Exporter) - 目前我使用这个
优点:布局非常现代,专为 dcgm-exporter 设计。它对 instance 和 gpu 的过滤逻辑写得比较规范,不容易出现变量失效的问题
监控重点:除了基础的温度和显存,它能清晰显示 Tensor Core 利用率(这对于运行 Qwen/Llama 这类大模型非常有意义,能看到模型是否真的在压榨 AI 核心)
最稳健:ID 12239 (NVIDIA DCGM Exporter Dashboard) - 官方仓库提供的原厂看板
优点:兼容性极强,几乎涵盖了所有 DCGM 导出的基础指标
缺点:UI 略显陈旧,且有时会因为 Prometheus 任务名(job name)不匹配导致需要手动调优变量
极简主义/单机优化:ID 24450 (DCGM Exporter Dashboard)
优点:去掉了大量不常用的深层指标(如 PCIe 错误率等),聚焦于:显卡型号、驱动版本、实时利用率、显存、功耗和风扇转速
加载模型
为确保两块 NVIDIA Tesla A2 GPU运算卡 能够充分利用,采用如下运行命令:
docker exec -it ollama ollama run qwen2.5-coder:32b-instruct-q4_K_M \
--set parameter num_ctx 24576 \
--set parameter num_gpu 999 \
--set parameter temperature 0.2
# Llama 3.3 是针对全球用户设计的模型,它的对齐(Alignment)策略基于国际通用的 AI 安全与伦理准则,回答风格客观、中立
docker exec -it ollama ollama run llama3.3:70b-instruct-q2_K
# 欧洲(法国)的 Mistral 24B 模型在双 A2 上可以运行 Q6_K (高精度) 甚至 FP16,且具有极强的指令遵循能力
docker exec -it ollama ollama run mistral-small3.2:24b-instruct-2506-q8_0
# 加载 qwen3-coder
docker exec -it ollama ollama run qwen3-coder-30b-a3b-instruct-q4_k_m
在使用 qwen2.5-coder:32b-instruct-q4_K_M 大约会使用 19GB - 20GB ,当使用2块A2卡时候,CUDA上下文和系统卡小大约占用 1GB - 2GB ,这样会有剩余 10GB - 12GB 显存用于KV Cache,能够支持大约 16,384 到 24,576 tokens 的上下文长度(取决于是否开启了 GQA 优化)
在使用 llama3.3:70b-instruct-q2_K 大约占用24GB,能预留8GB用于长文本对话(约8K上iawen),不过由于低比特量化(Q2)会导致模型在逻辑严密度上有5%-10%的衰减;如果使用 llama3.3:70b-instruct-q3_K_S 则占用31GB,虽然勉强能塞进显存,但是KV Cache空间极小(可能仅支持1k-2k上下文)
在使用 mistral-small:24b-instruct-q8_0 大约占用26GB,预留6GB用于上下文(8k-12k上下文长度),能够适合大多数通用对话、代码分析或技术咨询;如果使用 mistral-small3.2:24b-instruct-2506-q4_K_M 虽然只占用15GB,但是量化过程中会损失大约2-5%的逻辑推理能力,尤其在处理复杂指令或非中文语境下的细微差别是。使用 Q8 精度能在逻辑严密度上接近原始的FP16版本
备注
由于从Ollama下载模型非常缓慢甚至无法完成,我最终采用 ModelScope 来下载和导入模型,然后就可以在 open-webui 上选择对应模型进行问答
当对模型进行交流时,可以通过
nvidia-smi观察到两块 NVIDIA Tesla A2 GPU运算卡 运行时负载情况以及核心温度,我发现如果没有很好的散热,推理时GPU的问题会接近85度,所以必须通过 NVIDIA GPU散热风扇控制 来实现动态控制
Tue Mar 17 14:23:41 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 590.48.01 Driver Version: 590.48.01 CUDA Version: 13.1 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA A2 Off | 00000000:01:00.0 Off | 0 |
| 0% 84C P0 38W / 60W | 12981MiB / 15356MiB | 52% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA A2 Off | 00000000:02:00.0 Off | 0 |
| 0% 84C P0 45W / 60W | 12477MiB / 15356MiB | 61% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
监控调整
当使用 ID 15117 (NVIDIA DCGM Exporter) 看不到 Tensor core 的使用率:
检查Tensor Core面板可以看到Query是
DCGM_FI_PROF_PIPE_TENSOR_ACTIVE{instance=~"${instance}", gpu=~"${gpu}"}但是在Prometheus的Query中输入
DCGM_FI_PROF_PIPE_TENSOR_ACTIVE查不到任何内容直接检查
curl -s http://localhost:9400/metrics | grep -i "TENSOR"和curl -s http://localhost:9400/metrics | grep -i "PROF"可以看到输出是空,这表明默认的dcgm-exporter配置文件屏蔽了这些指标(为了降低采集压力)
实际上在 dcgm-exporter 容器内部 /etc/dcgm-exporter 目录下默认使用了 default-counters.csv 配置,这个配置只有基本计数器,另外还有一个 dcp-metrics-included.csv 则提供了Tensor Core, FP16, FP32等所有高级特性指标
修订运行命令:
docker run -d \
--gpus all \
--cap-add SYS_ADMIN \
-p 9400:9400 \
--network ai-network \
--name nvidia-exporter \
--restart always \
-e DCGM_EXPORTER_COLLECTORS=/etc/dcgm-exporter/dcp-metrics-included.csv \
nvidia/dcgm-exporter:latest
在启用了 dcp-metrics-included.csv 配置之后,就会看到 ID 15117 (NVIDIA DCGM Exporter) 几乎所有指标都能显示,除了 GPU Memory Temperature 是空的。这里无法显示GPU Memory温度不是dcgm-exporter的配置问题,而是因为 NVIDIA Tesla A2 GPU运算卡 作为精简版本推理卡,部分批次的A2不提供这个数据,即使 nvidia-smi -q 查询也看不到 Memory Current Temp (数据是 N/A)
在使用Ollama推理时,可以观察Grafana监控,看到GPU的温度、使用率以及内存带宽使用等情况
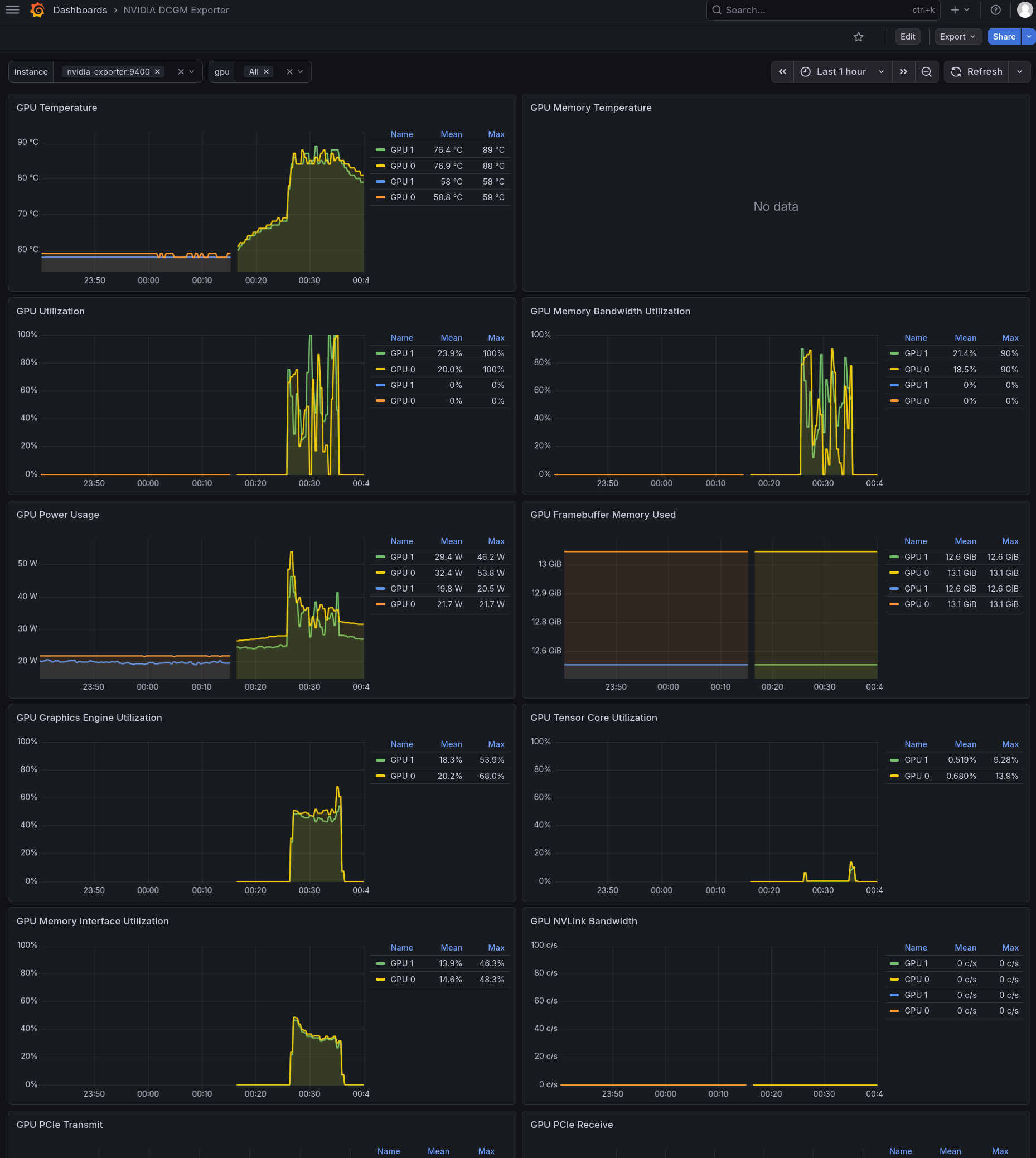
Tesla A2 推理时Grafana监控显示