MkDocs中文搜索
在使用MkDocs时候就会发现,默认只能搜索英文,中文内容是搜索不到的。虽然早期网上很多文章都说,只要在 mkdocs.yml 配置中启用 日语 搜索支持就能很好支持中文搜索,但是实际上依然几乎无效。
不过,2022年5月, Material Design theme for MkDocs 在 sponsor 仓库 Insiders 提供了内置支持中文搜索。不过,这个私有fork of Material for MkDocs需要加入Sponsorships(每月10美元)才能获取。
备注
Chinese search support – 中文搜索支持 文章提供了解决方法: 使用 jieba "结巴"中文分词 模块,可以较好进行中文分词及搜索。
这个 Insiders 版本可以非常轻松配置中文搜索支持,安装参考见 Chinese language support
如果你没有这笔经费,则可以参考 4行代码为Mkdocs实现简单中文搜索 - 原帖见 mkdocs search plugin supports zh_CN #2509
配置MkDocs中文搜索
安装 jieba "结巴"中文分词 模块:
jieba 模块pip install jieba
在
mkdocs.yml中配置separatorplugins: - search: lang: - en - ja separator: '[\s\-\.]+'
修订
lib/python3.10/site-packages/mkdocs/contrib/search/search_index.py:
import jieba # Chinese word separation module
class SearchIndex:
# The above remains unchanged
def _add_entry(self, title, text, loc):
"""
A simple wrapper to add an entry and ensure the contents
is UTF8 encoded.
"""
text = text.replace('\u3000', ' ') # Replace Chinese full space
text = text.replace('\u00a0', ' ')
text = re.sub(r'[ \t\n\r\f\v]+', ' ', text.strip())
# Split text into words
text_seg_list = jieba.cut_for_search(text) # Search engine mode, with higher recall rate
text = " ".join(text_seg_list) # join words with space
# Split title into words
title_seg_list = jieba.cut(title, cut_all=False) # Precise mode, more readable
title = " ".join(title_seg_list) # join words with space
self._entries.append({
'title': title,
'text': str(text.encode('utf-8'), encoding='utf-8'),
'location': loc
})
# The following remains unchanged
然后重新生成site
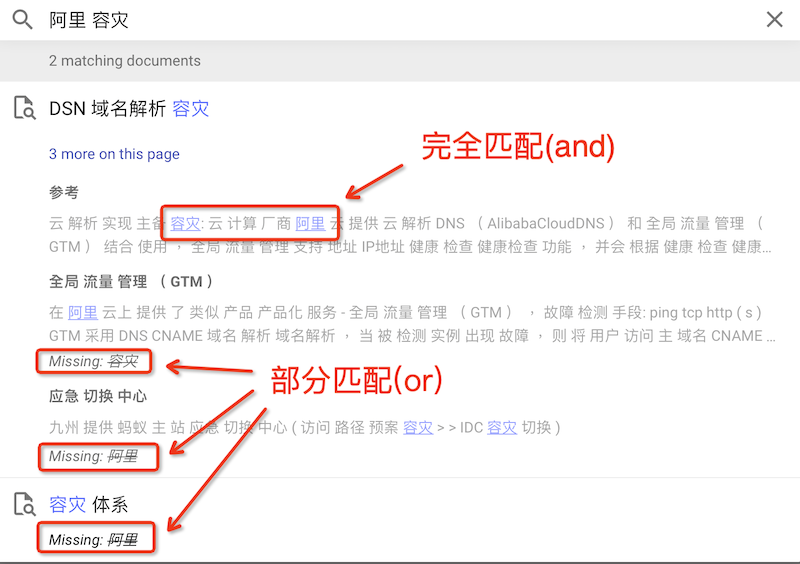
此时可以使用中文进行搜索,不过有限制:
每个单词只能2个中文字,超过两个字的词不能匹配,但是可以将多于2个字的词拆成以2个字为一个词的方式,多个词用空格连接进行搜索。例如,
阿里云拆分成阿里 云,这样就能够搜索到同时具备这2个词的段落,也能搜索到只具备阿里或云的段落。并且搜索结果会注明是同时满足还是missing了某个关键字以段落为搜索匹配范围
搜索可以通过空格来连接多个中文词汇,会同时展示
and和or结果: 举例,搜索阿里和容灾