Intel PCM Grafana¶
备注
Intel早期(2022年11月停止开发)还开发过一个 Snap Telemetry Framework (GitHub) 也可以和Grafana结合观测Intel处理器( Grafana Labs and Intel partner on Grafana and Snap ),可以参考实现方式。不过,目前看Intel PCM是Intel官方持续开发,并且在Linux主要发行版都提供,提供了非常详细的处理器监控。
备注
pcm/scripts/grafana/README.md 提供了通过脚本拉起 Grafana通用可视分析平台 和 Prometheus监控 容器的方法,不过我准备自己独立部署 Grafana 和 Prometheus (同时监控多项服务器目标),然后将 Intel pcm-exporter :Intel Performance Counter Monitor (Intel PCM) Prometheus exporter 采集数据集成
快速起步¶
在部署 Intel PCM Grafana 之前,需要先在被监控服务器上运行 pcm-exporter :Intel Performance Counter Monitor (Intel PCM) Prometheus exporter 提供 Metrics 输出
在 Intel PCM(GitHub) 源代码目录下提供了通过 Docker Atlas 运行的脚本,执行以下命令可以拉起2个容器分别运行 Prometheus监控 和 Grafana通用可视分析平台 并且传递参数可以指定监控服务器:
cd scripts/grafana
sudo sh start-prometheus.sh 192.168.6.200:9738
这里 scripts/grafana 目录下提供了多种 Docker Atlas 容器化运行的方法:
start.sh启动telegraf/influxdb/grafana容器start-prometheus.sh启动prometheus + grafana容器支持对多个目标服务器监控,只需要提供一个
targets.txt包含以下格式内容就可以运行sudo sh start-prometheus.sh targets.txthost1_ipaddress:pcmport host2_ipaddress:pcmport . . hostn_ipaddress:pcmport
启动完成后,检查容器 docker ps 可以看到2个运行容器:
docker ps 可以看到运行了 prometheus 和 grafana 两个容器¶CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
698140f6e520 grafana/grafana "/run.sh" 4 hours ago Up 3 hours 0.0.0.0:3000->3000/tcp, :::3000->3000/tcp grafana
eae45cdddc15 prom/prometheus "/bin/prometheus --c…" 4 hours ago Up 3 hours 0.0.0.0:9090->9090/tcp, :::9090->9090/tcp prometheus
然后就可以使用 浏览器访问 http://192.168.6.200:3000 看到 Grafana通用可视分析平台 ,使用
admin账号密码admin登陆(登陆后会提示立即修改密码)o
对于我的简陋的 Intel Xeon E5-2600 v3系列处理器 能够观察内存带宽使用,以及能耗,不过很多高级监控功能没有数据,应该是需要硬件支持才能实现:
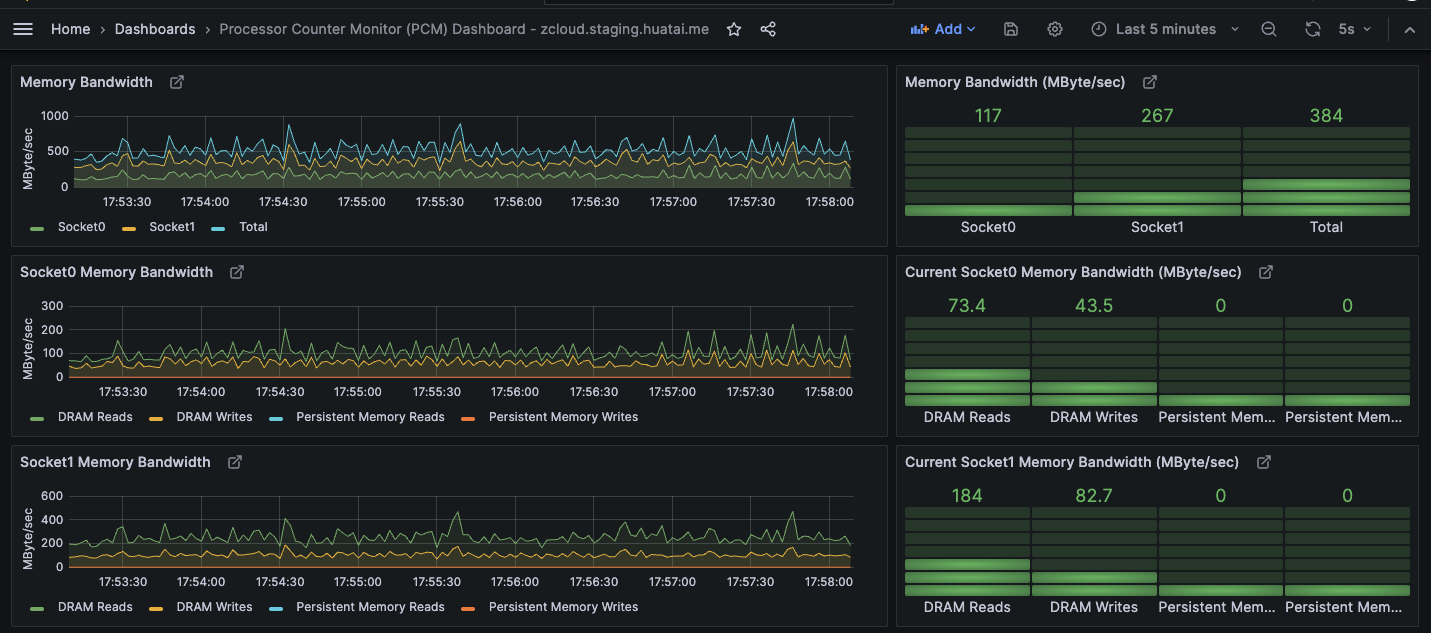
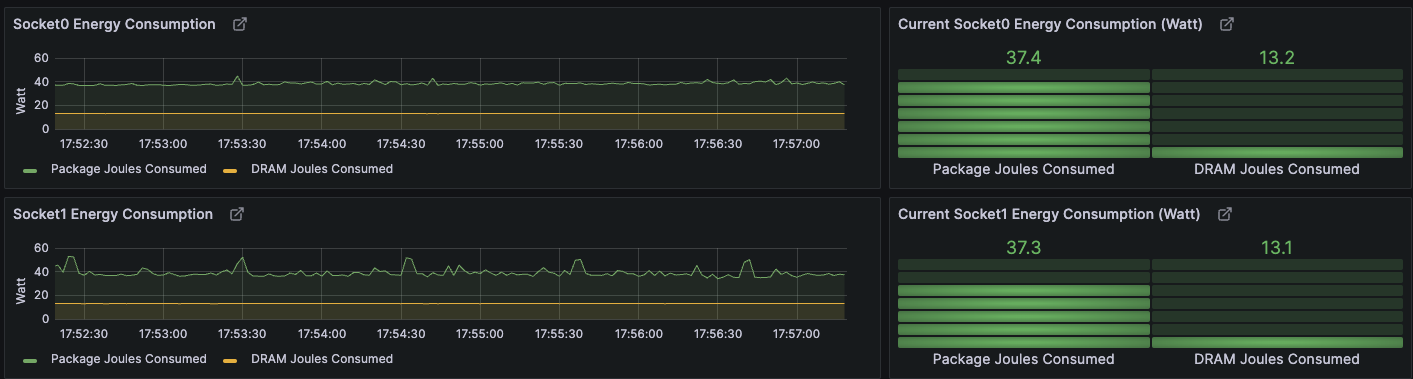
解析¶
登陆
prometheus容器内部检查配置,可以帮助我们理解配置方法为后续独立部署做准备:
docker exec 进入prometheus容器内部检查¶docker exec -it prometheus /bin/sh
找到
/etc/prometheus/prometheus.yml可以看到一个非常简单的配置:
/etc/prometheus/prometheus.yml¶# my global config
global:
scrape_interval: 2s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 2s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'pcm'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['192.168.6.200:9738']
- targets: ['192.168.6.201:9738']
- targets: ['192.168.6.202:9738']
也就是说,其实只需要添加目标地址,其他都采用了默认的 Prometheus监控 配置
此外,如果采用上文 targets.txt 来存储和传递监控目标服务器,则上述 /etc/prometheus/prometheus.yml 的 static_config 部分会依次添加IP地址
配置¶
既然已经验证过上述 快速起步 ,现在可以使用 Prometheus快速起步 部署的prometheus 和 安装Grafana 部署的grafana (也就是我直接在物理主机 zcloud 上通过 Systemd进程管理器 运行的监控系统)。配置非常简单:
在
/etc/prometheus/prometheus.yml的scrape_configs:段落添加:
zcloud 主机上监控配置 /etc/prometheus/prometheus.yml 只需要 scrape_configs: 段落添加¶ - job_name: 'pcm'
static_configs:
- targets:
- 192.168.6.200:9738
重启
prometheus服务:sudo systemctl restart prometheus
在Grafana的Dashboard中导入 Grafana Dashboard 17108: Processor Counter Monitor (PCM) Dashboard (这是第三方提供的Dashboard,其实和官方提供监控内容相似)
直接使用Intel PCM官方 pcm-exporter :Intel Performance Counter Monitor (Intel PCM) Prometheus exporter 提供的Dashboard JSON配置文件需要修订一下数据源,将:
"datasource": "prometheus",
替换成在之前导入Dashboard 17108中配置选择的数据源,例如(这里随机字符串就是我的prometheus数据源):
"datasource": {
"type": "prometheus",
"uid": "dacebb35-68e7-4f3c-aef2-de8d70cb8bd6"
},
就可以正常工作