Stable Diffusion 架构¶
备注
目前我对深度学习了解有限,本文很多内容仅仅是机翻摘抄,不少内容我目前还不理解。希望后续实践和学习能够帮助我更好掌握这些理论知识。
Stable Diffusion (稳定扩散) 是一种深度学习、文本到图像模型,于2022年发布。主要用于生成以文本描述为条件的详细图像,但也可以用于其他任务,例如修复图像或者由文本提示引导的图像翻译(image-to-image translations guided by a text prompt)。
Stable Diffusion是一种潜在的扩散模型,由LMU Munich 的 CompVis 小组开发的各种深度生成神经网络。Stable Diffusion的代码和模型权重已经公开发布,可以在大多数配置了至少8GB VRAM的普通GPU的消费级硬件上运行,这标志着Stable Diffusion和以往只能通过云服务访问的专有文本到图像模型(如DALL-E和Midjourney)完全不同。
备注
简而言之,Stable Diffusion给予个人能够在有限GPU硬件条件下实现文本引导的图像生成,具有很大的可玩性。
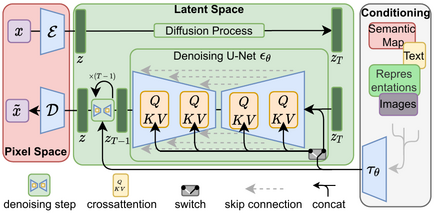
Stable Diffusion 组成¶
Stable Diffusion(稳定扩散)使用一种扩撒模型(diffusion model, DM)的变体,称为 潜在扩散模型 (latent diffusion model, LDM)。扩善模型是2015年推出的,起训练目标是消除消除高斯噪声在训练图像上的连续应用,可以将其稍微一系列去噪自动编码器。
Stable Diffusion由3部分组成:
变分自动编码器(variational autoencoder, VAE)
U-Net
可选的文本编码器(text encoder)
VAE编码器将图像从像素空间压缩到更小维度的潜在空间(ompresses the image from pixel space to a smaller dimensional latent space),以捕捉图像更基本的语义(capturing a more fundamental semantic meaning of the image)。在前向扩散过程中,高斯噪声被迭代地应用于压缩的潜在表示。
U-Net 块由 ResNet 骨干组成,对前向扩散的输出进行去噪以获得潜在表示。
VAE 解码器通过将表示转换回像素空间来生成最终图像。
去噪步骤可以灵活地以文本字符串、图像和其他形式为条件。 编码的调节数据通过交叉注意机制暴露给去噪 U-Nets。 对于文本条件,固定的、预训练的 CLIP ViT-L/14 文本编码器用于将文本提示转换为嵌入空间。
训练数据¶
Stable Diffusion 在 LAION-5B 中的成对图像和字幕上进行了训练,LAION-5B 是一个公开可用的数据集,来源于从网络上抓取的 Common Crawl 数据,其中 50 亿个图像-文本对根据语言进行分类,按分辨率过滤成单独的数据集, 包含水印的预测可能性,以及预测的“审美”分数(例如主观视觉质量)。 该数据集由德国非营利组织 LAION 创建,该组织接受 Stability AI 的资助。
训练过程¶
该模型最初是在 laion2B-en 和 laion-high-resolution 子集上训练的,最后几轮训练是在 LAION-Aesthetics v2 5+ 上完成的,这是 LAION-Aesthetics Predictor V2 预测的 6 亿张带字幕图像的子集。该模型在 Amazon Web Services 上使用 256 个 Nvidia A100 GPU 进行了总计 150,000 GPU 小时的训练,成本为 600,000 美元。
限制¶
Stable Diffusion 在某些情况下存在退化和不准确的问题。 该模型的初始版本是在由 512×512 分辨率图像组成的数据集上训练的,这意味着当用户规范偏离其“预期”512×512 分辨率时,生成图像的质量会明显下降。
2.0 版更新 稳定扩散模型后来引入了以 768×768 分辨率本地生成图像的能力。
由于数据库中缺乏代表性特征,该模型没有充分训练来理解人类的四肢和面部,促使模型生成此类图像可能会混淆模型。 除了人类的肢体,生成动物肢体也被观察到具有挑战性,在尝试生成马的图像时观察到的失败率为 20-25%。
为了为数据集中未包含的新用例定制模型,例如生成动漫角色(“waifu diffusion”),需要新数据和进一步训练。 通过额外的再训练创建的稳定扩散的微调适应已用于各种不同的用例,从医学成像到算法生成的音乐。
但是,这种微调过程对新数据的质量很敏感: 低分辨率图像或与原始数据不同的分辨率不仅不能学习新任务,而且会降低模型的整体性能。 即使在高质量图像上额外训练模型,个人也很难在消费电子产品中运行模型。 例如,waifu-diffusion 的训练过程至少需要 30 GB 的 VRAM,这超过了消费类 GPU 提供的通常资源,例如 Nvidia 的 GeForce 30 系列大约有 12 GB。
此外,Stable Difussion的实际使用结果完全取决于训练,也就是公开的模型是创建者训练出来的,主要是在带有英文描述的图像上训练的。也就是生成的图像强化了社会偏见
备注
个人使用Stable Diffusion的难点主要是缺乏进一步训练的能力,也就是说Stable Diffusion要真正能够实用,最大的难点是标记训练,这需要大量的人力投入和硬件投入。所以个人难以突破现有的训练结果,也就只能使用已经完成的训练进行一些简单操作。
实际上这是目前深度学习的局限性,其生成结果完全受到训练数据的影响,非常容易出现偏差。
最终用户微调¶
为了解决模型初始训练的局限性,最终用户可以选择实施额外的训练,以微调生成输出以匹配更具体的用例。
可以通过三种方法将用户可访问的微调应用于稳定扩散模型检查点:
可以从用户提供的图像集合中训练“嵌入”,并允许模型在生成提示中使用嵌入名称时生成视觉上相似的图像。 嵌入基于特拉维夫大学的研究人员在 Nvidia 的支持下于 2022 年开发的“文本倒置”概念,其中模型的文本编码器使用的特定标记的向量表示与新的伪词相关联。 嵌入可用于减少原始模型中的偏差,或模仿视觉风格。
“超网络”是一种小型预训练神经网络,应用于较大神经网络中的各个点,指的是 NovelAI 开发人员 Kurumuz 于 2021 年创建的技术,最初用于文本生成转换器模型。 超网络将结果导向特定方向,允许基于稳定扩散的模型模仿特定艺术家的艺术风格,即使艺术家未被原始模型识别; 他们通过寻找重要的关键区域(例如头发和眼睛)来处理图像,然后在次级潜在空间中修补这些区域。
DreamBooth 是一种深度学习生成模型,由 Google Research 和波士顿大学的研究人员于 2022 年开发,可以微调模型以生成描绘特定主题的精确、个性化的输出,通过一组描绘主题的图像进行训练
在线Demo¶
简单尝试了一下在线Demo,以我在 Life Atlas 中选择的 海子 的 「面朝大海,春暖花开」 英文版生图:

可以看到 stable diffusion 会堆砌元素,按照一定风格组合成图片,但是说不上好看:
训练数据影响风格
prompt产生一些差异