CUDA Cores vs. Tensor Cores
在机器学习领域,训练一个ML model(机器学习模型)需要对大型数据进行筛选。但是随着数据集的数量、复杂度和交叉关系的增加,处理能力的需求呈指数级增长(surges exponentially)。
深度学习(DL)是机器学习(ML)的一个重要子集,使用人工神经网络(ANN)进推理研究。因此,深度学习本质上更加依赖于大量数据来为模型提供输入。传统的 CPU 无法处理庞大的机器学习数据集,也无法提供ML模型训练的计算能力,所以ML通常采用高级GPU,通过内置的CUDA core和Tensor core 阵列来完成机器学习任务(训练和推理)。
GPU
图形处理单元(Graphical Processing Units, GPUs)是用于沉浸式视频游戏(immersive video games),电影和其他视觉媒体中用于呈现丰富2D/3D图形和动画的专用硬件。由于GPU能够超高效进行并行的浮点计算,已经成为海量数据处理和ML模型训练的最佳选择。NVIDIA开发了用于通用和专用处理的 NVIDIA CUDA 和 Tesnor 核心GPU,成为ML领域主要的硬件供应商。
CUDA Cores
CUDA(Compute Unified Device Architecture, 计算统一设备架构)是NVIDIA于2007年发布的专有、特殊设计的GPU核心,大致相当于CPU核心。虽然不如CPU核心通用和强大,但是CUDA的核心优势是数量巨大,并且能够同时并行地对不同数据集进行计算。由于高级GPU具备数百甚至数千CUDA核心,尽管每个CUDA核心和CPU一样只能在每个时钟周期执行一个操作,但是GPU的SIMD架构使得成百上千个CUDA核心能够同时处理一个数据集,从而在更短时间内完成数据处理。CUDA技术对数据分析、数据可视化以及AI/ML开发场景带来极大改进。CUDA代码支持多种语言开发:C, C++, Fortran, OpenCL 和 Direct Compute等语言,以支持CUDA的GPU进行通用计算和数据处理。CUDA指令集还提供对NVIDIA GPU的虚拟指令的直接访问软件和程序,CUDA core GPU还支持Direct 3D, OpenGL等图形API,以及OpenCL和OpenMP等编程框架。
CUDA Cores是实时计算、计算密集型3D图形、游戏开发、密码散列(cryptographic hashing)、物理引擎和数据科学计算的主要硬件,在机器学习和深度学习领域,以及TB级别数据训练上,GPU也是重要核心硬件。
Tensor Cores
备注
上述视频通过 Sphinx文档嵌入YouTube视频 实现,很有用的一个 Sphinx文档 插件;类似还有 Sphinx文档嵌入视频
Tensor Cores是特殊设计的NVIDIA GPU核心,用于动态计算(dynamic calculations)和混合精度计算(mixed-precision computing)。Tensore cores可以在提供整体性能的同时保持准确性(accelerate the overall performance while simultaneously preserving accuracy)。
备注
NVIDIA将Tensor Core加速的 高维矩阵(张量Tensor)计算称为混合精度计算(mixed-precision computing),因为输入矩阵的精度为半精度(两个4*4 FP16矩阵相乘),然后将结果添加到4*4 FP16或FP32矩阵中,最终输出新的4*4 FP6或FP32矩阵(可以达到完全精度)。
属于 Tensor (张量) 定义了一种数据类型,可以保存或表示所有形式的数据,可以将其视为存储多维数据集的容器(a container to store multi-dimensional datasets)。
Tensor cores利用融合乘加算法(fused multiply-addition algorithms),将两个FP16 和/或 FP32 矩阵相乘并相加,从而显著加快计算速度,而且对模型的最终效果几乎没有损失。虽然矩阵乘法在逻辑上很简单,但是每次计算都需要寄存器和缓存来存储临时计算(interim calculations),从而使得整个计算量非常庞大。所以Tensore cores特别适合训练庞大的ML/DL模型。
目前已经发布了4代Tensor cores:
第一代Tensor cores使用Volta(伏打) GPU微架构(V100): 第一代Tensor cores提供了FP16数字格式的混合精度计算,通过V100的640个Tensor Cores,比早期的Pascal系列GPU相比,第一代Tensor cores可以提供高达5倍的性能提升。
第二代Tensor cores使用Turing(图灵) GPU微架构(T100?): 第二代Tensor cores执行速度是Pascal GPU的32倍,并且将FP16计算扩展到Int8, Int4 和 Int1,从而提高计算精度
第三代Tensor cores使用Ampere(安培) GPU微架构(A100): 第三代Tensor cores增加了对bfloat16, TF32和FP64精度的支持,进一步扩展了Volta和Turing微架构的潜力
第四代Tensor cores使用Hopper(霍波) GPU微架构(H100): 第四代Tensor cores可以处理FP8精度,在FP16、FP32和FP64计算方面比上一代A100快三倍,在8位浮点数学运算方面快六倍
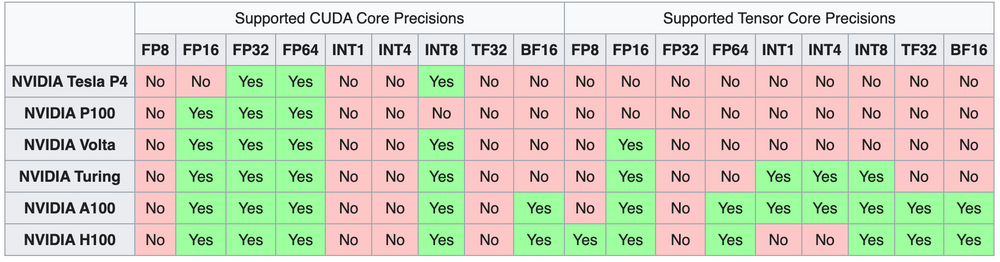
不同代NVIDIA数据中心GPU支持的计算精度
我的 Nvidia Tesla P10 GPU运算卡 相当于 P4/P40 ,不支持 FP16 ,所以和 Nvidia Tesla P100 GPU运算卡 相比较,更适合作为推理卡使用。
备注
Harnessing GPU Tensor Cores for Fast FP16 Arithmetic to Speed up Mixed-Precision Iterative Refinement Solvers 介绍了采用NVIDIA Tensor Cores的FP16加速混合精度计算的解决方案
备注
NVIDIA的GPU微架构都是以历史上著名的科学家、数学家和计算机科学家命名:
Volta(伏打): 1799年,意大利物理学家Alessandro Volta发明了第一款电池(Vlotaic Pile 伏特堆)
Truing(图灵): 艾伦·麦席森·图灵(Alan Mathison Turing,1912年6月23日~1954年6月7日),英国数学家、逻辑学家,被称为计算机科学之父,人工智能之父。
Ampere(安培): 安德烈·玛丽·安培(André-Marie Ampère,1775年1月20日 — 1836年6月10日),法国物理学家、化学家和数学家,在电磁作用方面的研究成就卓著,被麦克斯韦誉为“电学中的牛顿”
Hopper(霍波): 格蕾丝·霍波 (Grace Hopper,1906-1992),是计算机语言领域的开拓者,发明了世界上第一个编译器——A-0 系统,被称为“计算机软件工程第一夫人”。1945年,Grace Hopper在 Mark Ⅱ中发现了一只导致机器故障的飞蛾,从此“bug” 和 “debug” (除虫) 便成为计算机领域的专用词汇。
CUDA Cores 和 Tensor Cores的差别
随着越来越依赖海量数据集来进行更准确的模型训练和推理,CUDA cores GPU 被发现处于中等水平。 因此,Nvidia 引入了 Tensor cores。 Tensor cores 在一个时钟周期内执行多项操作表现出色。 因此,在机器学习操作方面,Tensor cores 优于 CUDA cores。
如何使用Tensor Cores
在使用 ollama 进行大模型推理的 在Docker中Ollama使用NVIDIA A2 GPU运行大模型 ,可以看到监控显示Tensor Cores没有任何负载: 推理后端(Inference Backend)的工作模式与硬件特性之间不匹配。
由于运行的量化类型(K-Quants)是 q4_K_M 和 q2_K ,是GUFF格式特有的量化方式。GUFF的这些量化权重的反量化(De-quantization)和矩阵运算,目前在 llama.cpp 中主要通过 CUDA Cores(SIMD)来完成,而不是 Tensor Cores 。
Tensor Core对输入数据的格式要求极其苛刻(通常要求 FP16, BF16 或 特定的 INT8/INT4 格式)。GGUF的位宽是不规则的,为保证精度,它在计算时会先在显存里把权重还原成FP16,然后交给CUDA Cores处理。
如果Ollama没有开启 FlashAttention ,系统会回退到标准的计算模式,完全绕过Tensor Core。但是即使开启而来 FlashAttention 也不能保证能够激活Tensor Core,因为Ollama官方Docker镜像为了 极端的兼容性 ,内部打包的 llama.cpp 往往采用了保守的编译策略:
缺少架构特定优化 :要激活 NVIDIA Tesla A2 GPU运算卡 的Tensor Core,编译时需要指定
-DGGML_CUDA_F16=ON且目标算力需要匹配sm_86。官方镜像为了能够让Pascal和Maxwell老卡能够跑,通常会回退到最稳妥的FP32数据对齐限制 : Tensor Core对矩阵的维度(M,N,K)有严格的 8或16倍数对齐 要求。Ollama在处理不同模型的Head size时,如果对齐没有做好,会自动回退到CUDA Core以确保计算正确
解决的方法是采用 vLLM ,因为vLLM使用了 FlashAttention 2 的原生实现,并且PageAttention算子是专门为Tensor Core优化的。并且,需要采用AWQ格式的模型文件( Hugging Face )