Grafana配置快速起步¶
完成 安装Grafana 或者 使用Helm 3在Kubernetes集群部署Prometheus和Grafana 之后,配置Grafana
安装Grafana 使用社区提供的apt软件仓库安装,则默认端口是
3000首次登陆用户名和密码都是admin,会立即提示修改密码,请修改并保存密码使用Helm 3在Kubernetes集群部署Prometheus和Grafana 采用社区提供的 helm 安装在Kubernetes集群,通过 在反向代理后面运行Grafana ,默认
admin密码prom-operator
添加Prometheus数据源(metrics)¶
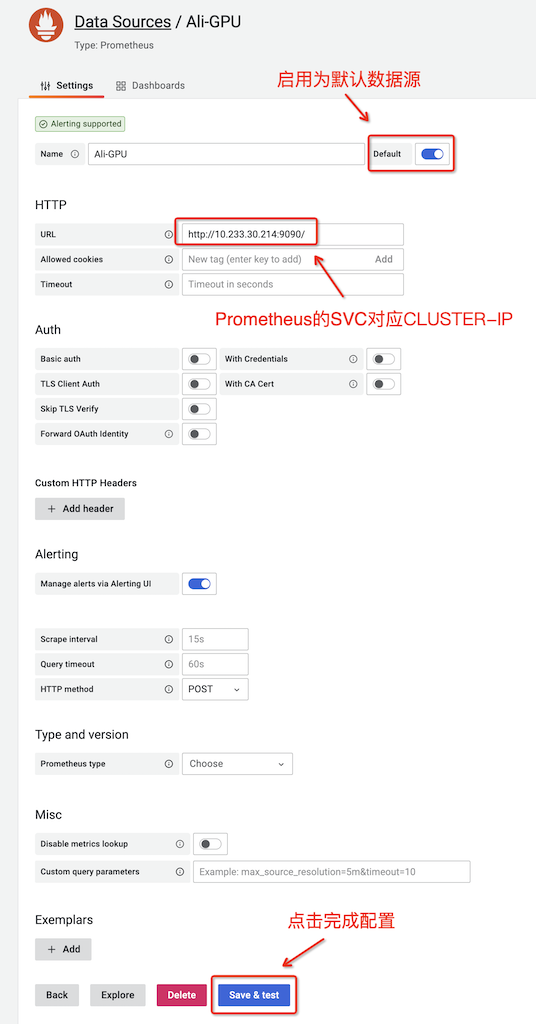
Prometheus是Grafana默认支持的核心组件,对于同时部署了 Prometheus 和 Grafana,所以添加数据源选择 Prometheus 类型后:
在导航栏,选择
Configuration图标,然后点击Data Sources点击
Add data source在数据源列表中,点击选择
Prometheus在URL栏,填写 http://localhost:9090 ( 安装Grafana ) 或者 Prometheus实际运行的IP地址,例如 Kubernetes 集群内部地址 http://10.233.30.214:9090/ ( 使用Helm 3在Kubernetes集群部署Prometheus和Grafana )
这个访问 Prometheus 的地址可以通过 kubectl get svc 观察 prometheus 对应的 CLUSTER-IP ,例如 在 使用Helm 3在Kubernetes集群部署Prometheus和Grafana :
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 24h
kubernetes ClusterIP 10.233.0.1 <none> 443/TCP 5d8h
prometheus-operated ClusterIP None <none> 9090/TCP 24h
stable-grafana ClusterIP 10.233.19.177 <none> 80/TCP 24h
stable-kube-prometheus-sta-alertmanager ClusterIP 10.233.20.3 <none> 9093/TCP 24h
stable-kube-prometheus-sta-operator ClusterIP 10.233.13.186 <none> 443/TCP 24h
stable-kube-prometheus-sta-prometheus ClusterIP 10.233.30.214 <none> 9090/TCP 24h
stable-kube-state-metrics ClusterIP 10.233.13.91 <none> 8080/TCP 24h
stable-prometheus-node-exporter ClusterIP 10.233.32.207 <none> 9100/TCP 24h
然后点击
Save & Test
Grafana读取Prometheus发生插件错误¶
备注
这段请忽略,我记录是为了后续探索社区提供的helm安装,默认配置的用途。后续再修订…
我在 使用Helm 3在Kubernetes集群部署Prometheus和Grafana 遇到一个奇怪的问题,默认内部就有一个 Prometheus 数据源,并且URL是 http://stable-kube-prometheus-sta-prometheus.default:9090/ ,而且在数据源上方有一个提示内容:
Provisioned data source
This data source was added by config and cannot be modified using the UI. Please contact your server admin to update this data source.
我以为这是一个需要修改的 Prometheus 源时,但是我发现这个配置只有一个 Test 按钮,并且点击是错误提示:
Error reading Prometheus: An error occurred within the plugin
开始使用¶
备注
其实我最初是 迷惘 的,因为我见过很多美观的 Grafana 监控视图…
社区提供的Grafana+Prometheus组合 使用Helm 3在Kubernetes集群部署Prometheus和Grafana 内置了很多针对Kubernetes的监控面板,完全是开箱即用的,其实无需配置。(我最初想多了,以为难以上手)
只需要上文配置好 Prometheus监控 的数据源(这个我倒是遇到一些安全限制导致的采集问题,例如 Prometheus访问监控对象metrics连接被拒绝 / Prometheus监控Kubelet, kube-controller-manager 和 kube-scheduler ),然后直接在 General 搜索栏中选择内置的Kubernetes面板就可以了。以下是一些非常直观的Kubernetes监控面板:
Node Export / Nodes:
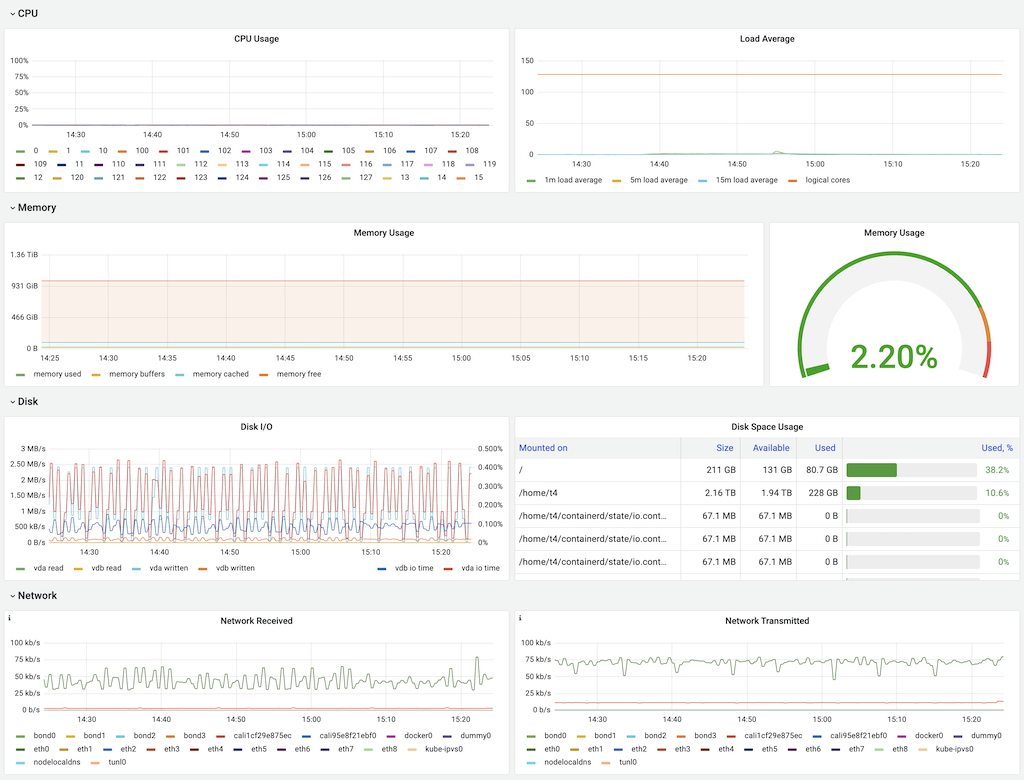
基于Namespace的K8s计算资源使用
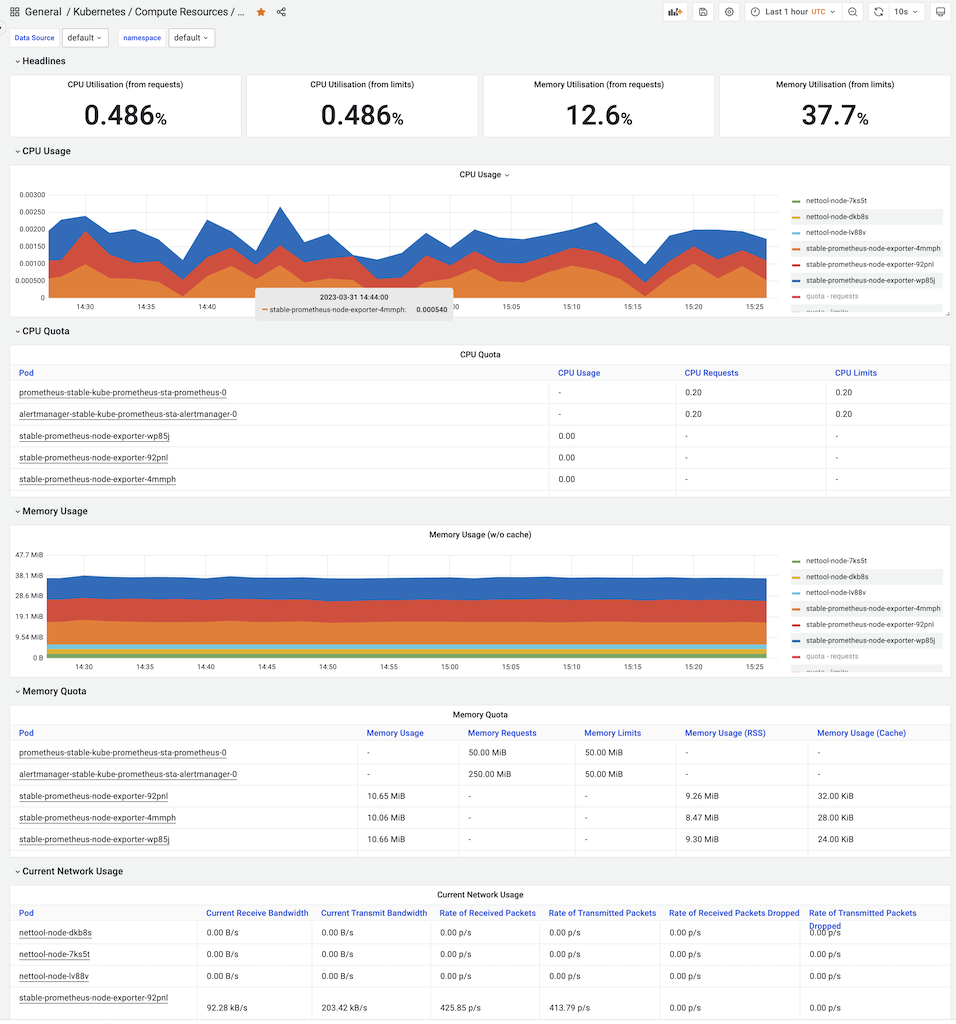
此外,针对 GPU Kubernetes ,采用 DCGM-Exporter 可以如同采集CPU数据一样采集GPU数据,可以集成到Grafana中实现完善的监控。
更多dashboards¶
Grafana.com 维护了一系列 共享Grafana dashboards ,可以下载并用于自己的Grafana部署。
注意,下载的 JSON 文件需要手工编辑并修正 datasource: 配置项以便反映正确连接的 Prometheus监控 服务器数据源。然后使用 "Dashboards" → "Home" → "Import" 导入dashboard。
Prometheus graph¶
添加一个
Metrics,可以使用任意一个 Prometheus 的metircs,例如,之前测试过rate(node_cpu_seconds_total{mode="system"}[1m])(也就是节点的system负载)