内核概览¶
备注
有关Linux内核的历史和传奇,在很多书籍和网络资料中都有,已经耳熟能详了。所以,我这里仅提纲挈领整理 一些我感兴趣的特性,以便后续学习内核开发时索引。
内核定义¶
内核是硬件和软件之间的
中间层内核将应用程序的请求传递给硬件,并充当
底层驱动程序,对系统的设备进行寻址内核将计算机设备抽象到一个高层次上,可以视为一台
增强型计算机计算机系统中有多个程序并发运行,所以可以将内核视为
资源管理程序将共享资源(CPU时间、磁盘空间、网络连接等)分配到各个系统进程
保证系统的完整性
内核提供了面向系统的指令库,
系统调用对于应用程序就像普通函数一般
Linux内核特性¶
支持动态加载内核模块
支持对称多处理器(symmetrical multiprocessor, SMP)
Linux内核是抢占式的(
preemptive): 即使进程在内核中运行也可以抢占Linux内核支持线程: 对于内核不区分线程和常规进程,将线程视为共享资源的进程
提供一个具有设备类型的面向对象的设备模式,热插拔实践,以及一个用户空间的设备文件系统(sysfs)
微内核 vs. 宏内核¶
微内核: 只有最基本功能直接由中央内核(微内核)实现,所有其他功能都委托给独立进程,这些进程通过明确定义的通信接口与中心内核通信
微内核的优点:系统各部分彼此清晰划分,可以动态扩展和在运行时切换总要组件。
微内核缺点:组件间支持复杂通信需要额外的CPU时间
宏内核:宏内核是构建系统内核的传统方法。宏内核的全部代码,包括所有子系统(内存管理、文件系统、设备驱动程序)都打包到一个文件中。内核中每个函数都可以访问内核中所有其他部分。
宏内核优点:性能比微内核高
宏内核缺点:编程时容器导致源代码出现复杂的嵌套
备注
现代的Linux内核(宏内核)已经引入了动态内核模块,可以运行时插入到内核代码中或者移除,弥补了宏内核的一些缺陷。
进程、进程切换、调度¶
传统上,Unix操作系统的每个进程都在CPU的 虚拟内存 中分配地址空间,每个进程的地址空间完全独立,因此进程不会意识到彼此的存在。 从进程的角度来看,它认为自己是系统中唯一的进程 。
Linux是多任务系统,系统中 真正同时在运行的进程数量最多不会超过CPU数量 ,所以内核会在很短的时间间隔在不同进程之间切换:
内核借助CPU帮助负责
进程切换:必须给各个进程造成一种错觉,即CPU总是可用的在撤销进程的CPU资源之前保存进程所有与状态有关的要素,并将进程置于空闲状态
重新激活进程时,则从保存的状态原样恢复
内核负责确定如何在进程间共享CPU时间:重要的进程获得的CPU时间多于次要进程。这种确定哪个进程运行多长时间的过程称为
调度。
进程(process)¶
Linux进程是一种层次系统 pstree 输入如下:
init─┬─auditd───{auditd}
├─crond
├─login───bash
├─master─┬─pickup
│ └─qmgr
├─5*[mingetty]
├─rsyslogd───3*[{rsyslogd}]
├─sshd───sshd───sshd───bash───pstree
└─udevd───2*[udevd]
备注
上述 pstree 的输出内容是 CentOS 6执行效果,我选择 CentOS 6是为了基于 Kernel 2.6.x 进行学习。对于 CentOS 7开始,使用了 Systemd进程管理器 ,则 0 号进程由 init 替换为 systemd 。
UNIX操作系统有两种创建新进程的机制: fork 和 exec
fork 可以创建当前进程的一个副本:
父进程和子进程只有PID不同,父进程内存的内容被复制(至少从程序角度看如此)
Linux使用了
写时复制(copy on write)技术来加速父进程的内存复制:将内存复制操作延迟到父进程或子进程想某个内存页面陷入数据之前,在只读访问情况下父进程和子进程可以共用同一内存页
exec 将一个新进程加载到当前进程的内存中并执行
旧程序的内存页将刷出,其内容将替换为新的数据
然后开始执行新程序
线程(thread)¶
线程也称为轻量级进程:
一个进程由若干个线程组成
线程间共享相同的数据和资源,但可能执行程序中不同但代码路径
可以将进程看成一个正在执行的程序,而线程则是与主程序并行运行的程序函数或例程
Linux使用 clone 方法创建线程:
clone工作方法类似fork但是启用了精确的检查,以确认哪些资源与父进程共享、哪些资源为线程独立创建
命名空间(namesapce)¶
命名空间(namespace)使得不同的进程可以看到不同的系统视图:
启用namespace以后,全局资源就具有不同的分组
每个namespace可以包含一个特定的PID集合,或者提供文件系统的不同视图
在某个namespace中挂载的卷不会传播到其他namespace中
namespace被用于容器技术:
在容器内部看是一个完整的Linux系统
容器之间彼此隔离
与完全虚拟化解决方案(如KVM)不同,容器环境只需要运行一个内核来管理所有容器
地址空间¶
地址空间的最大长度与实际可用的物理内存数量无关,因此被称为 虚拟地址空间 :
对系统的每个进程,地址空间内只有自身一个进程,无法感知到其他进程存在
Linux将虚拟地址空间划分为两部分:
内核空间
用户空间
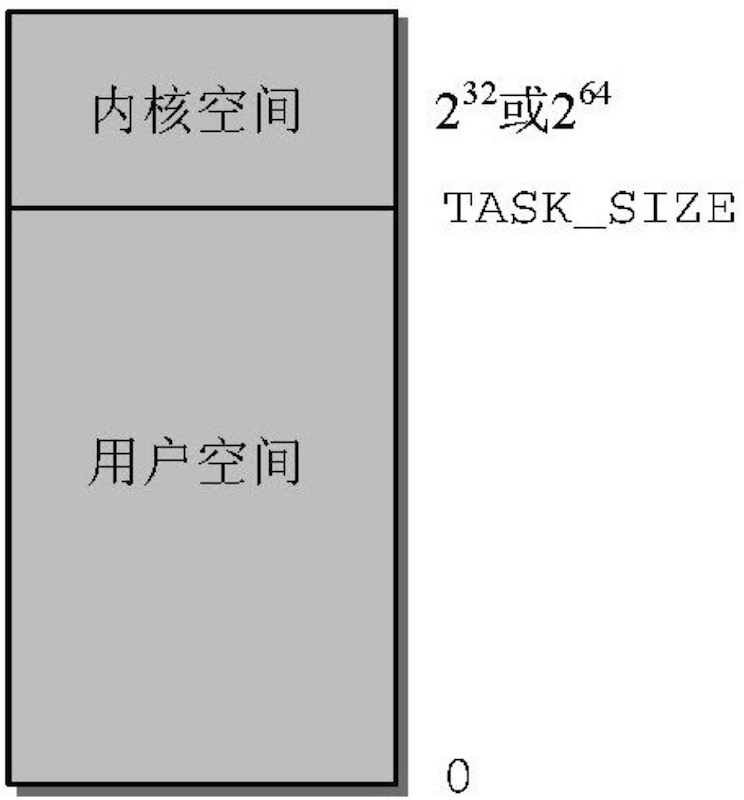
每个用户进程都有自身对虚拟地址范围:从0到
TASK_SIZE用户空间之上到区域(从
TASK_SIZE到 2的32次方 或者 2的64次方)保留给内核专用,用户进程不能访问TASK_SISE是一个计算机体系结构常熟,把地址空间按比例分为两部分:IA-32系统中,地址空间在3GB处划分,即进程的虚拟地址空间是3GB。由于虚拟地址的总空间是4GB,所以内核有1GB可用
64位系统,实际使用位数一般小于64位,如42位或47位
特权级别¶
内核把虚拟地址空间划分为两部分,因此能够保护系统进程,使之彼此隔离。
英特尔处理器有4中特权级别,但Linux只使用两种不同但状态:
核心态
用户态
这两种状态的关键区别在于对高于 TASK_SIZE 的内存区域的访问:
用户态禁止访问内核空间
用户进程不能操作或读取内核空间的数据,也无法执行内核空间的代码(防止进程修改彼此的数据而互相干扰)
从用户态切换到核心态是通过 系统调用 的特定转换手段完成:
普通进程想要执行任何影响整个系统的操作(例如操作输入/输出装置),则只能借助于系统调用向内核发出请求
内核首先检查进程是否
允许执行想要的操作,然后代表进程执行所需操作,接下来返回到用户状态
除了代表用户程序执行系统操作,内核还可以由异步硬件中断激活,然后在 中断上下文 中运行:
与在进程上下文中运行的主要区别是,在中断上下文中运行时,内核不能访问虚拟地址空间中用户空间部分
因为中断可能随机发生,中断发生时可能任意用户进程处于活动状态,由于该进程基本与中断的原因无关,所以内核无权访问当前用户空间内容。
在中断上下文中运行,内核必须比正常情况下更加谨慎
在中断上下文中运行是,内核不能进入睡眠状态(编写中断处理程序要特别注意)
除了普通进程,系统中还有 内核线程 ,内核线程也不与任何特定的用户空间进程相关联,因为也无权处理用户空间。
与在中断上下文运行的内核不同,内核线程可以进入睡眠状态,也可以像系统中的普通进程一样被调度器跟踪。
内核线程可以用于多种用户,如:
内存和块设备之间的数据同步
帮助调度器在CPU上分配进程
核心态和用户态切换:
应用程序执行系统调用时,CPU切换到核心态,内核负责完成其请求
在核心态时,内核可以访问虚拟地址空间的用户部分
系统调用完成后,CPU切换回用户态
硬件中断也会使CPU切换到核心态,但是这种情况下内核不能访问用户空间
ps 命令输出中很容易识别内核线程:内核线程的名称都位于方括号内
ps fax
显示输出:
PID TTY STAT TIME COMMAND
2 ? S 0:00 [kthreadd]
3 ? S 0:00 \_ [migration/0]
4 ? S 0:00 \_ [ksoftirqd/0]
5 ? S 0:00 \_ [stopper/0]
...
901 ? S 0:00 \_ [kauditd]
920 ? S 0:00 \_ [flush-253:0]
1 ? Ss 0:01 /sbin/init
509 ? S<s 0:00 /sbin/udevd -d
832 ? S< 0:00 \_ /sbin/udevd -d
840 ? S< 0:00 \_ /sbin/udevd -d
1174 ? S<sl 0:00 auditd
1197 ? Sl 0:00 /sbin/rsyslogd -i /var/run/syslogd.pid -c 5
1263 ? Ss 0:00 /usr/sbin/sshd
1501 ? Ss 0:00 \_ sshd: huatai [priv]
1504 ? S 0:00 \_ sshd: huatai@pts/0
1505 pts/0 Ss 0:00 \_ -bash
1576 pts/0 R+ 0:00 \_ ps fax
...
1379 tty6 Ss+ 0:00 /sbin/mingetty /dev/tty6
1433 ? Ss 0:00 login -- huatai
1437 tty1 Ss+ 0:00 \_ -bash
注意:多处理器系统上,许多线程启动时指定了CPU,并限制只能在某个特定的CPU上运行。从内核线程名称后面面的斜线和CPU编号可以看到。
虚拟和物理地址空间¶
用页表来为物理地址分配虚拟地址:
虚拟地址关系到进程的用户空间和内核空间
物理地址则用来寻址实际可用的内存
物理内存页通常称为 页帧 ,而 页 则专指虚拟地址空间中的页。
页表¶
用来将虚拟地址空间映射到物理地址空间的数据结构称为 页表
由于需要关联虚拟地址和物理地址,如果使用简单的数组项来指向关联的页帧,特别是每个进程都需要自己的页表,则会导致数组极为庞大。不过,由于虚拟地址空间大部分区域都没有使用,也就不需要关联到页帧,所以实际使用的是功能相同但内存使用量少很多但模型: 多级分页 。
这里的简化模型是 三级 页表(在Linux中采用了四级页表):
参考¶
「深入Linux内核架构」