Ceph后端存储引擎BlueStore
从Ceph Luminous v12.2.z 开始,默认采用了新型的BlueStore作为Ceph OSD后端,用于管理存储磁盘。
BlueStore的优势:
对于大型写入操作,避免了原先FileStore的两次写入 (注意,很多FileStore将journal日志存放到独立到SSD上,也能够获得类似的性能提升,不过分离journal的部署方式是绕开FileStore的短板)
对于小型随机写入,BlueStore比 FileStore with journal 性能还要好
对于Key/value数据BlueStore性能明显提升
当集群数据接近爆满时,BlueStore避免了FileStore的性能陡降问题
在BlueStore上使用raw库的小型顺序读性能有降低,和BlueStore不采用预读(readahead)有关,但可以通过上层接口(如RBD和CephFS)来实现性能提升
BlueStore在RBD卷或CephFS文件中采用了copy-on-write提升了性能
备注
当前在Red Hat Ceph 3.x中, Red Hat Ceph BlueStore 后端是作为技术预览提供。
micron公司 Ceph BlueStore vs. FileStore: Block performance comparison when leveraging Micron NVMe SSDs. 评测概况:
4KB随机写IOPS性能增强 18% ,平均延迟降低 15%,以及 99.99% 长尾延迟最大降低 80%
4KB随机读性能根据BlueStore配置的更高队列得到更好的性能
micron公司提供了 Micron Accelerated Ceph Storage Solutions 可以作为Ceph硬件架构部署的参考。
BlueStore工作原理
Ceph OSD执行两个功能:在网络中和其他OSD之间复制数据(多副本),以及在本地存储设备上存储数据。
传统的Ceph OSD是将数据存储到现有的文件存储模块,例如XFS文件系统。但是这样的性能开销较大,因为需要实现Ceph数据到POSIX的转换。
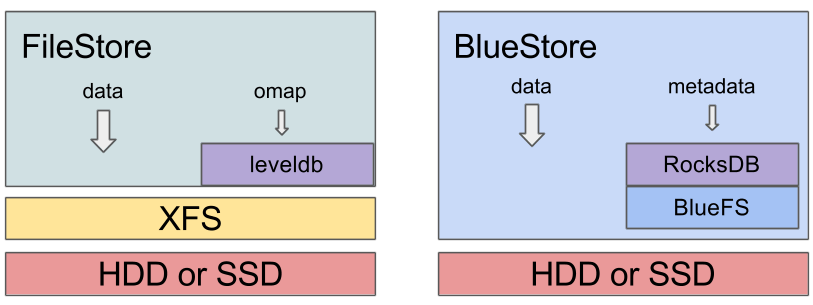
BlueStore是在底层裸块设备上建立的存储系统,内建了RocksDB key/value 数据库用于管理内部元数据。一个小型的内部接口组件称为 BludFS 实现了类似文件系统的接口,以便提供足够功能让RocksDB来存储它的"文件"并向BlueStroe共享相同的裸设备。
和之前的FileStore不同的是,BlueStore类似分区和挂载点,例如在一个FileStore OSD,你会看到类似:
$ lsblk
…
sdb 8:16 0 931.5G 0 disk
├─sdb1 8:17 0 930.5G 0 part /var/lib/ceph/osd/ceph-56
└─sdb2 8:18 0 1023M 0 part
…
$ df -h
…
/dev/sdb1 931G 487G 444G 53% /var/lib/ceph/osd/ceph-56
$ ls -al /var/lib/ceph/osd/ceph-56
…
drwxr-xr-x 180 root root 16384 Aug 30 21:55 current
lrwxrwxrwx 1 root root 58 Jun 4 2015 journal -> /dev/disk/by-partuuid/538da076-0136-4c78-9af4-79bb40d7cbbd
可以看到上述FileStore有一个很小的日志分区(journal partition),通常这个日志分区位于一个独立的SSD上,一个日志系统链接(journal symlink)从数据目录指向这个独立的日志分区,并且一个当前目录包含了所有实际对象文件。
对比之下,在BlueStore OSD,你会看到:
$ lsblk
…
sdf 8:80 0 3.7T 0 disk
├─sdf1 8:81 0 100M 0 part /var/lib/ceph/osd/ceph-75
└─sdf2 8:82 0 3.7T 0 part
…
$ df -h
…
/dev/sdf1 97M 5.4M 92M 6% /var/lib/ceph/osd/ceph-75
…
$ ls -al /var/lib/ceph/osd/ceph-75
…
lrwxrwxrwx 1 ceph ceph 58 Aug 8 18:33 block -> /dev/disk/by-partuuid/80d28eb7-a7e7-4931-866d-303693f1efc4
在BlueStore中目录数据目录技术一个微小分区(100MB),而系统链接到一个块设备上,也就是BlueStore存储数据的块设备,所以IO是从ceph-osd进程直接访问raw设备的(使用Linux异步libaio结构)。
虽然不能和以前一样直接查看BlueStore中的对象文件,但是如果OSD停止,依然可以通过FUSE mount OSD数据:
mkdir /mnt/foo
ceph-objectstore-tool --op fuse --data-path /var/lib/ceph/osd/ceph-75 --mountpoint /mnt/foo
多设备
BuleStore可以组合慢速和快速设备,类似FileStore,并通常能够更多使用快速设备。在FileStore中,日志设备只用于写,通常位于较快多SSD。在BlueStore中,内建的日志需要保持稳定,更为轻量级,类似元数据日志只记录小型写入。
BlueStore可以管理最多3个设备:
main设备(块系统链接)存储目标队形以及元数据db设备是可选的,存储metadata(RocksDB)WAL设备可选只用于内部日志(RocksDB预写日志)
通常建议使用尽可能多的SSD空间给OSD使用,并且将SSD用于 block.db 设备。当使用 ceph-disk 结合 --block.db 参数:
ceph-disk prepare /dev/sdb --block.db /dev/sdc
如果没有采用独立的 block.db 设备,则默认存储在主设备,占用1%空间。这个预先配置空间可以通过 bluestore_block_db_size 配置选项修改。如果使用3个设备(节约成本):主设备使用HDD,db设备使用SSD,最小的NVDIMM设备用于WAL。
备注
详细的BlueStore配置信息可以参考 BlueStore configuration guide
内存使用
由于BlueStore是作为OSD的用户空间实现,所以自己管理缓存,通过一些内存管理工具实现。
BlueStore的底线是 bluestore_cache_size 配置选贤,控制每个OSD所使用的BlueStore缓存消耗的内存。默认是每个HDD后端OSD使用1GB内存,而SSD后端OSD则使用3GB内存。不过你可以根据自己环境来调整合适值。
警告
内存记账当前是不完善的:使用了tcmalloc,会导致有时候实际分配超过设置值。随着时间推移堆栈会碎片化,而内存碎片化使得部分释放内存不能返回给操作系统。结果就是,通常会出现BlueStore(和OSS)认为使用的内核和进程实际使用内存(RSS)差异有时候出现1.5倍差异。对比 ceph-osd 的进程RSS消耗内存和通过 ceph daemon osd.<id> dump_mempools 输出的值就可以看到这个差异。目前ceph项目还在解决这个问题。(2017年9月)
校验
BlueStore计算、存储和验证校验所有存储的数据和元数据。任何时候从磁盘读取数据,数据在输出给系统其他部分(或用户)使用之前都会使用校验来验证数据正确性。默认使用 crc32c checksum,也提供其他校验选项( xxhash32 , xxhash64 ),甚至支持使用降级的 crc32c (例如,使用标准校验32位数据中的8位或者16位)来降低元数据跟踪(牺牲了数据可靠性)。也支持完全关闭数据校验(但不推荐此方式)。详细可参考 文档的checksum部分 。
压缩
BlueStore可以使用zlib, snappy 或者 lz4 实现透明压缩。默认BlueStore关闭了压缩功能,但是可以全局激活或者针对特定存储池激活,也提供了当RADOS客户端访问数据时选择性激活。详情请参考 文档的压缩章节 。
转换现有集群到BlueStore
在一个单一集群中每个OSD可以同时包含一些FileStore OSD和一些BlueStore OSD。一个升级的集群可以持续完成转换,即新OSD采用BlueStore来不断轮转替换旧的FileStore,通过不断下线旧的FileStore并添加新的FileStore(默认启用BlueStore)利用数据健康恢复将多副本数据复制回来。这个过程可以平滑安全实现,详情请参考 BlueStore migration 。
参考
Ceph BlueStore vs. FileStore: Block performance comparison when leveraging Micron NVMe SSDs.
Maximize the Performance of Your Ceph Storage Solution - Racespace的私有云客户案例,采用NVMe存储协议和持久化内存加速的BlueStore存储后端