Presto vs. Impala¶
OLTP vs. OLAP¶
OLTP¶
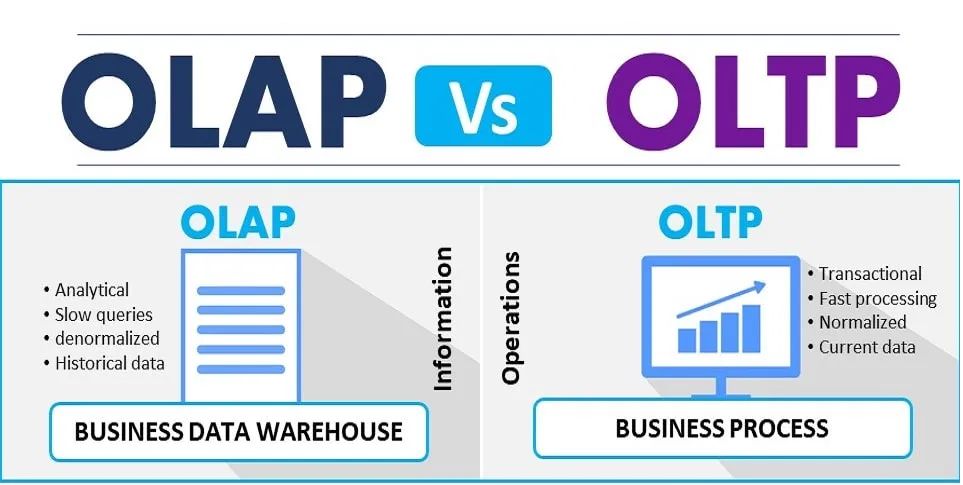
OLTP(on-line transaction processing)是联机事物处理
OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事物处理,记录即时的 增、删、改、查 ,也称为实时系统(Real time System)。
衡量联机事物处理系统的一个重要性能指标是系统性能,具体体现为实时响应时间(Response time) ,即用户在终端上输入数据到系统对这个请求给出返回结果所需要的时间。
OLTP特点 - OLTP实时性要求高: OLTP数据库要求事务应用程序仅写入所需数据,以便尽快处理完单个事务。 - 数据量不是很大: 和OLAP相比较数据集小很多 - 交易一般确定: OLTP是对确定性的数据进行存取 - 支持大量并发用户定期添加和修改数据: 要求严格的事务完整、安全性
OLAP¶
OLAP(on-line analytical processing)是连机分析处理
OLAP是数据仓库的核心部分,是对大量已有OLTP形成的历史数据进行加工和分析,读取较多但更新较少的一种分析型数据库,用于处理商业只能、决策支持等重要的决策信息。
OLAP支持复杂的分析操作,侧重决策支持,并提供直观易懂的查询结果。典型的OLAP应用就是动态报表系统。
OLAP的特点: - 实时型要求不高: 很多应用是每天更新一次数据 - 数据量巨大: 因为OLAP是动态查询,所以用户也许要通过很多数据的统计之后才能得到想要知道的信息。例如时间序列分析等等,所以处理的数据量巨大。 - 重点在于决策支持: 查询一般是动态的,也就是允许用户随时提出查询的要求。OLAP通过一个重要的概念
维来构建一个动态查询的平台,提供用户自己决定需要知道什么信息。
OLAP和OLTP之间的关系可以认为OLAP是依赖于OLTP的,因为OLAP分析的数据都是由OLTP所产生的,也可以看作OLAP是OLTP的一种延展,一个让OLTP产生的数据发现价值的过程。
Presto vs. Impala¶
Presto 和 Impala 都是开源OLAP引擎。
Presto¶
备注
现在 Presto 项目演进成 Trino分布式大数据查询
Fackbook开源的presto大数据OLAP引擎,分布式SQL查询引擎(MPP, Massive Parallel Processing)。Presto的设计理念源于一个叫Volcano的并行数据库,该数据库提出了一个并行执行SQL的模型,它被设计为用来专门进行高速、实时的数据分析。
Presto 可以查询包括 Hive、Cassandra 甚至是一些商业的数据存储产品。单个 Presto 查询可合并来自多个数据源的数据进行统一分析。Presto是一个OLAP的工具,擅长对海量数据进行复杂的分析;但是对于OLTP场景,并不是Presto所擅长,所以不要把Presto当做数据库来使用。
Presto是一个SQL计算引擎,分离计算层和存储层,其不存储数据,通过Connector SPI实现对各种数据源(Storage)的访问。
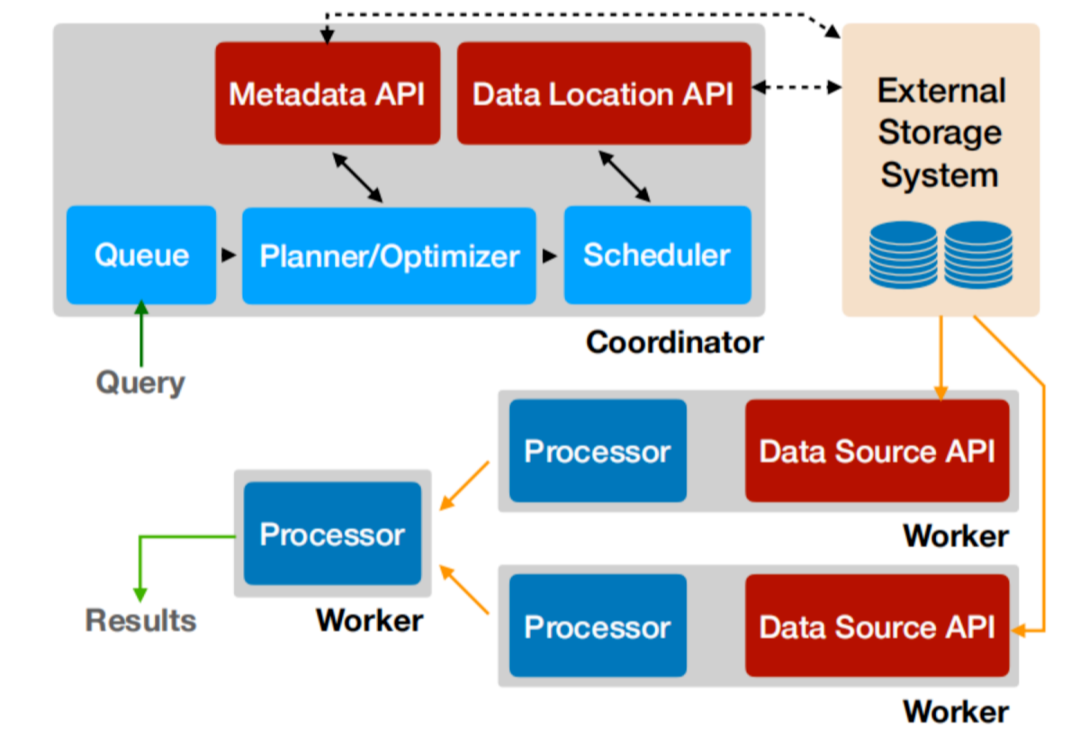
Presto 是一个分布式系统,运行在集群环境中,完整的安装包括一个协调器 (coordinator) 和多个 workers:
Coordinator负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行
Worker节点负责实际执行查询任务
Presto提供了一套Connector接口,用于读取元信息和原始数据
Presto 内置有多种数据源,如 Hive、MySQL、Kudu、Kafka 等
Presto 的扩展机制允许自定义 Connector,从而实现对定制数据源的查询: 例如配置了Hive Connector,需要配置一个Hive MetaStore服务为Presto提供Hive元信息,Worker节点通过Hive Connector与HDFS交互,读取原始数据。
查询通过例如 Presto CLI 的客户端提交到协调器,协调器负责解析、分析和安排查询到不同的 worker 上执行。
Presto低延时原理¶
Presto是一个交互式查询引擎,其性能出众的原因如下:
完全基于内存的并行计算
流水线
本地化计算
动态编译执行计划
小心使用内存和数据结构
GC控制
无容错
PrestoDB 和 PrestoSQL¶
最早Presto 由Facebook公司开源,Github链接为 PrestoDB 。但是因为Facebook对Presto相关开发优先级为公司内部需求为主,导致社区活跃性和很多Issues得不到及时解决。
2019年Facebook内部主要负责Presto的人单独出来成立了新公司。社区也重新创建,Github链接为 PrestoSQL 。
两个社区都成立了各自的基金会,在版本迭代中新的功能和解决的问题在实现上有相同也有所不同。目前在国内的一些互联网公司采用了presto来做OLAP。
滴滴在2020年9月升级到PrestoSQL 最新版本(340版本)原因是:
PrestoSQL社区活跃度更高,PR和用户问题能够及时回复
PrestoDB主要主力还是Facebook维护,以其内部需求为主
PrestoDB未来方向主要是ETL相关的,通过Spark兜底,ETL功能依赖Spark、Hive
Presto 接入了查询路由 Gateway,Gateway会智能(HBO(基于历史的统计信息)及JOIN数量来区分查询大小)选择合适的引擎:
用户查询优先请求Presto(查询时间小于3分钟)
如果查询失败,会使用Spark查询
如果依然失败,最后会请求Hive
备注
ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。ETL一词较常用在数据仓库,但其对象并不限于数据仓库。
Presto业务场景介绍¶
Presto在滴滴的探索与实践 - Hive SQL查询加速 - 数据平台Ad-Hoc查询 - 报表(BI报表、自定义报表) - 活动营销 - 数据质量检测 - 资产管理 - 固定数据产品
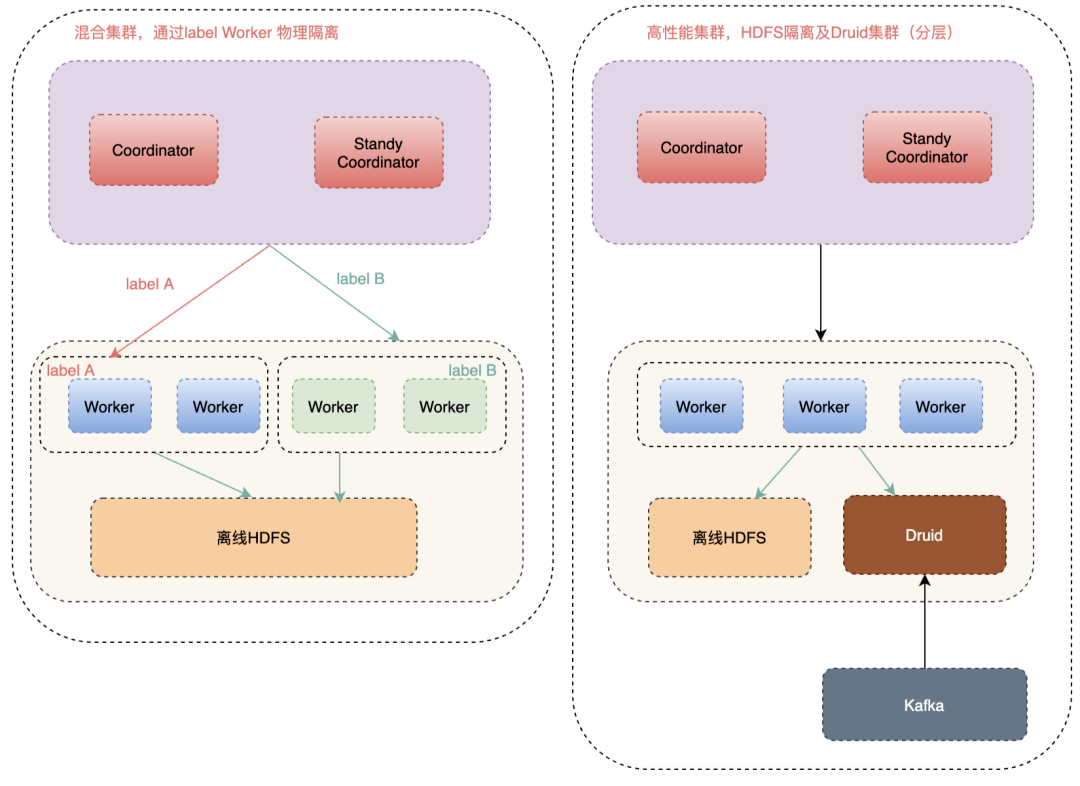
滴滴使用Presto分为混合集群和高性能集群:
混合集群共用HDFS集群: 与离线Hadoop大集群混合部署,通过指定Label来做到物理集群隔离。
高性能集群: HDFS是单独部署的,且可以访问Druid, 使Presto 具备查询实时数据和离线数据能力。
备注
在滴滴内部大多集群是混合集群,因为单独建立高性能集群维护成本很高。为避免混布集群性能影响,调度模块支持Presto动态打Label,动态调度指定的 Label 机器。如上图中,Label A和Label B会分别调度到不同对应标签的工作节点,避免相互干扰。
Presto on Druid Connector¶
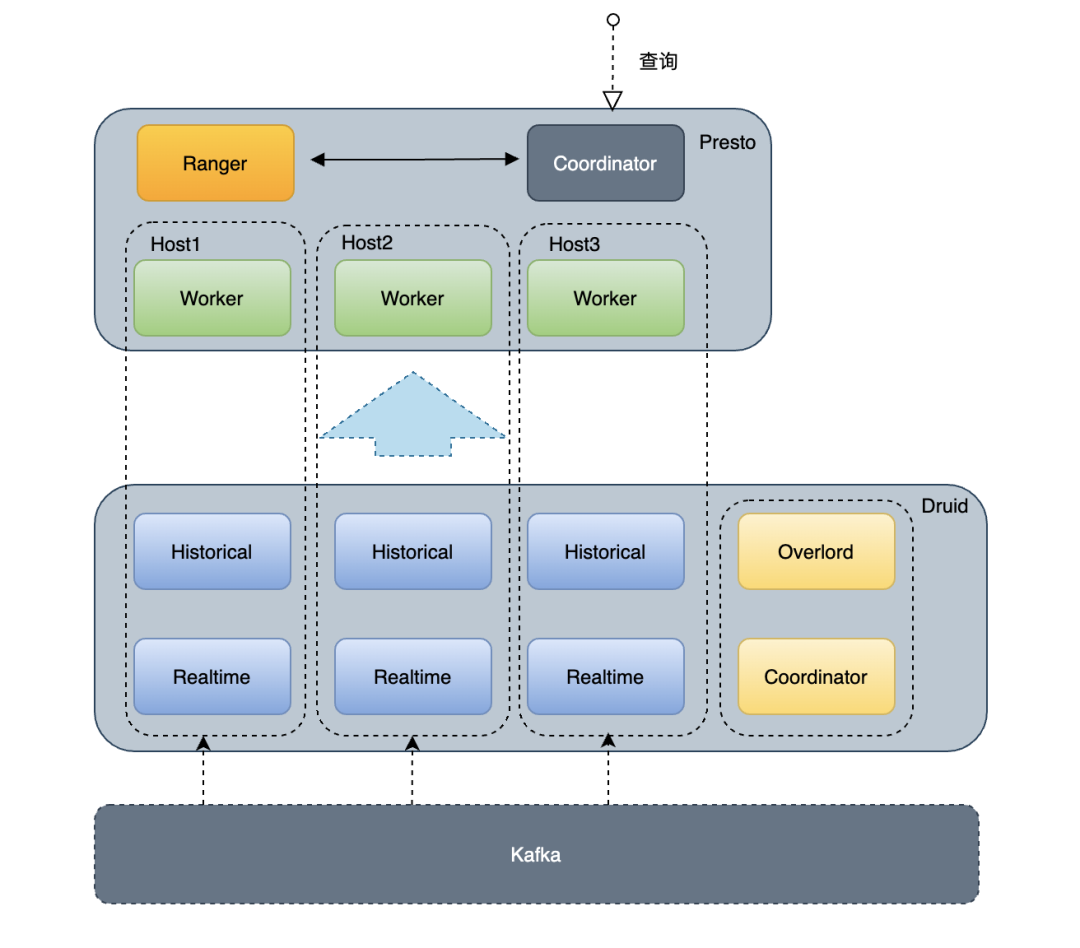
Presto on Druid Connector - 结合 Druid 的预聚合、计算能力(过滤聚合)、Cache能力,提升Presto性能(RT与QPS) - 让 Presto 具备查询 Druid 实时数据能力 - 为Druid提供全面的SQL能力支持,扩展Druid数据的应用场景 - 通过Druid Broker获取Druid元数据信息 - 从Druid Historical直接获取数据
备注
Presto在滴滴的探索与实践 还总结了维护Presto稳定的一些经验总结,但目前我限于没有实践,暂时无法提供总结,请参阅原文。
Impala¶
Impala是Cloudera公司推出,提供对HDFS、Hbase数据的高性能、低延迟的交互式SQL查询功能。Impala基于Hive,使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点,是CDH平台首选的PB级大数据实时查询分析引擎。
Impala优点:
基于内存运算,不需要把中间结果写入磁盘,省掉了大量的I/O开销。
无需转换为Mapreduce,直接访问存储在HDFS,HBase中的数据进行作业调度,速度快。
使用了支持Data locality的I/O调度机制,尽可能地将数据和计算分配在同一台机器上进行,减少了网络开销。
支持各种文件格式,如TEXTFILE 、SEQUENCEFILE 、RCFile、Parquet。
可以访问hive的metastore,对hive数据直接做数据分析。
Impala缺点:
对内存的依赖大,且完全依赖于hive。
实践中,分区超过1万,性能严重下降。
只能读取文本文件,而不能直接读取自定义二进制文件。
每当新的记录/文件被添加到HDFS中的数据目录时,该表需要被刷新。
Impala架构¶
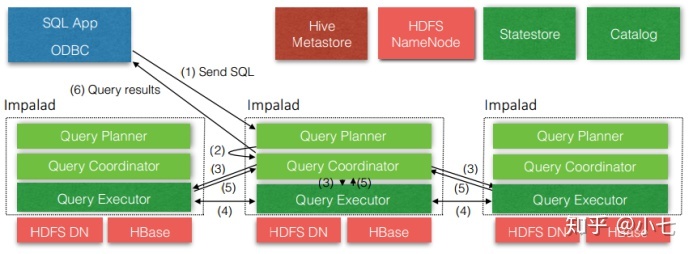
Impala自身包含三个模块:Impalad、Statestore和Catalog,除此之外它还依赖Hive Metastore和HDFS:
Impalad: - 接收client的请求、Query执行并返回给中心协调节点 - 子节点上的守护进程,负责向statestore保持通信,汇报工作
Catalog: - 分发表的元数据信息到各个impalad中 - 接收来自statestore的所有请求
Statestore: - 负责收集分布在集群中各个impalad进程的资源信息、各节点健康状况,同步节点信息 - 负责query的协调调度