在Kuternetes集成GPU可观测能力
GPU现在已经成为Kubernetes环境重要资源,我们需要能够通过类似 Prometheus监控 这样的统一监控来访问GPU指标以监控GPU资源,就像传统的CPU资源监控一样。
备注
如果在Kubernetes集群已经部署了 NVIDIA GPU Operator ,那么会自动在GPU节点上安装好 DCGM-Exporter 。所以,采用 NVIDIA GPU Operator 是 NVIDIA/dcgm-exporter GitHub官方 推荐的部署方式( Note: Consider using the NVIDIA GPU Operator rather than DCGM-Exporter directly. )。
实际上,我尝试了 NVIDIA/dcgm-exporter GitHub官方 提供的通过Helm chart安装 DCGM-Exporter ,没有成功:
helm repo add gpu-helm-charts https://nvidia.github.io/dcgm-exporter/helm-charts
helm repo update
helm install --generate-name gpu-helm-charts/dcgm-exporter
提示报错:
Error: INSTALLATION FAILED: unable to build kubernetes objects from release manifest: resource mapping not found for name: "dcgm-exporter-1679911060" namespace: "default" from "": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
ensure CRDs are installed first
不过,如果 安装NVIDIA GPU Operator 就直接解决了这个问题,会自动完成GPU节点的 dcgm-exporter 安装。
对于一些生产环境,可能不会部署完整的 NVIDIA GPU Operator (而采用自己的解决方案),这种情况依然可以独立部署 DCGM-Exporter ,本文即参考官方文档实现这种部署模式。此时在GPU节点上本机安装,也就是既不使用 NVIDIA GPU Operator 也不容器化驱动程序( Docker运行NVIDIA容器 )
NVIDIA驱动
在物理主机或者虚拟机(GPU PassThrough)中,需要安装 NVIDIA Drivers(驱动) ,采用 通过Linux发行版软件仓库方式安装NVDIA CUDA驱动
备注
根据操作系统版本不同,主要分为 RedHat Linux 和 Ubuntu Linux 系,采用不同的包管理方式
Ubuntu安装NVIDIA驱动
执行Ubuntu添加仓库:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.0-1_all.deb
sudo dpkg -i cuda-keyring_1.0-1_all.deb
sudo apt-get update
安装 NVIDIA CUDA 驱动:
sudo apt-get -y install cuda-drivers
RHEL/CentOS 7安装NVIDIA驱动
执行RHEL/CentOS 7仓库添加:
# CentOS7可能需要安装编译工具链, RHEL7通常已经安装
sudo dnf install -y tar bzip2 make automake gcc gcc-c++ pciutils elfutils-libelf-devel libglvnd-devel iptables firewalld vim bind-utils wget
# 安装EPEL仓库
sudo yum install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
# 对于RHEL7还需要激活一些可选仓库(CentOS7无需此操作)
sudo subscription-manager repos --enable="rhel-*-optional-rpms" --enable="rhel-*-extras-rpms" --enable="rhel-ha-for-rhel-*-server-rpms"
# 安装CUDA仓库公钥
distribution=$(. /etc/os-release;echo $ID`rpm -E "%{?rhel}%{?fedora}"`)
# 设置仓库
ARCH=$( /bin/arch )
sudo yum-config-manager --add-repo http://developer.download.nvidia.com/compute/cuda/repos/$distribution/${ARCH}/cuda-$distribution.repo
# 安装Kernel头文件
sudo yum install -y kernel-devel-$(uname -r) kernel-headers-$(uname -r)
# 清理缓存
sudo yum clean expire-cache
安装 NVIDIA CUDA 驱动:
sudo yum -y install cuda-drivers
安装 容器运行时(Container Runtimes)
NVIDIA提供了多种 NVIDIA容器运行时 支持,可以选择:
上述任意一种 容器运行时(Container Runtimes) 都支持,选择安装了runtime之后,就需要安装对应的NVIDIA Container Toolkit
安装NVIDIA Container Toolkit
NVIDIA提供了多种 NVIDIA容器运行时 支持,例如 Docker , containerd运行时(runtime) , cri-o容器运行时 ,请按照你的Kubernetes集群实际 容器运行时(Container Runtimes) 对应安装 NVIDIA Container Toolkit:
安装Kubernetes
部署 Vanilla Kubernetes :
Kubernetes集群引导(高可用) (以及相关实践)
安装 NVIDIA Device Plugin
安装NVIDIA Device Plugin (独立安装 nvida-device-plugin )
部署 helm:
version=3.12.2
wget https://get.helm.sh/helm-v${version}-linux-amd64.tar.gz
tar -zxvf helm-v${version}-linux-amd64.tar.gz
sudo mv linux-amd64/helm /usr/local/bin/helm
添加
nvidia-device-pluginhelm仓库:
helm repo add nvdp https://nvidia.github.io/k8s-device-plugin \
&& helm repo update
部署
NVIDIA Device Plugins:
helm upgrade -i nvdp nvdp/nvidia-device-plugin \
--namespace nvidia-device-plugin \
--create-namespace \
--version 0.13.0
正式开始
GPU可观测性
NVIDIA的GPU可观测性也是建立在 Prometheus监控 基础上,构建的完整数据采集,时序数据库存储metrics,并通过 Grafana通用可视分析平台 实现可视化。此外, Prometheus监控 包含了 Alertmanager 提供了告警创建和管理。Prometheus 通过 kube-state-metrics (KSM) 和 Node Exporter 分别为Kubernetes API对象输出集群级别的 Metrics 和节点级别的 Metrics (例如CPU使用率)。
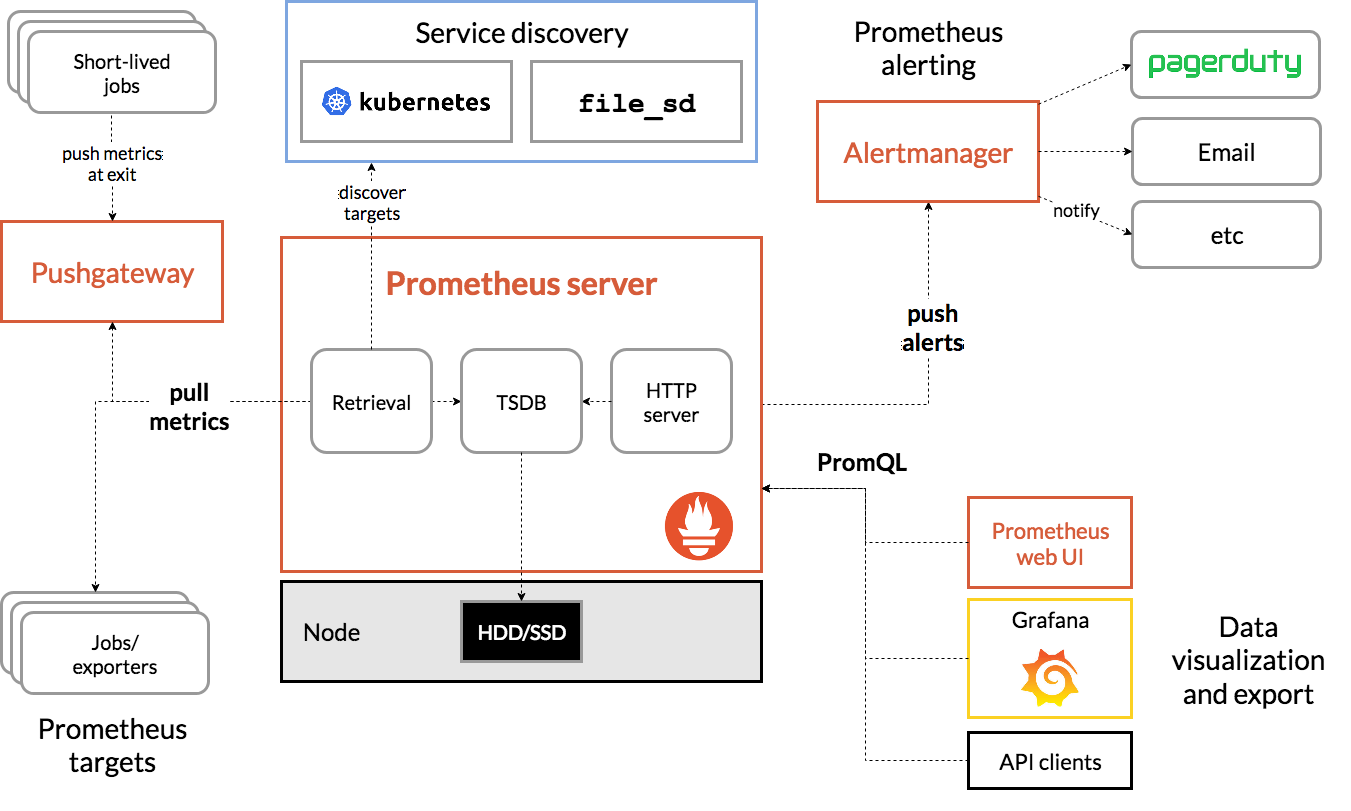
Prometheus 架构
要从Kubernetes采集GPU可观测性数据,建议使用 DCGM-Exporter : 基于 NVIDIA DCGM (Data Center GPU Manager) 的 DCGM-Exporter 为 Prometheus监控 输出了GPU Metrics 并且能够被 Grafana通用可视分析平台 可视化。 DCGM-Exporter 架构充分发挥了 KubeletPodResources API 并且采用 Prometheus 能够抓取的格式输出 GPU metrics。此外,还包括了一个 ServiceMonitor 的公开endpoints。
部署Prometheus
实际上NVIDIA官方文档中介绍的 GPU可观测性 方案所采用的 Prometheus 部署方式就是采用社区提供的 使用Helm 3在Kubernetes集群部署Prometheus和Grafana 。NVIDIA做了一些微调:
安装 helm :
curl -LO https://git.io/get_helm.sh
chmod 700 get_helm.sh
./get_helm.sh
添加 Prometheus 社区helm chart:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
NVIDIA对社区方案参数做一些调整(见下文),所以先导出 chart 使用的变量(以便修订):
helm inspect values 输出Prometheus Stack的chart变量值helm inspect values prometheus-community/kube-prometheus-stack > kube-prometheus-stack.values
将metrics端口
30090作为NodePort输出在每个节点(实际建议修订)
prometheus:
## Configuration for Prometheus service
##
service:
annotations: {}
labels: {}
clusterIP: ""
## Port for Prometheus Service to listen on
##
port: 9090
## To be used with a proxy extraContainer port
targetPort: 9090
## List of IP addresses at which the Prometheus server service is available
## Ref: https://kubernetes.io/docs/user-guide/services/#external-ips
##
externalIPs: []
## Port to expose on each node
## Only used if service.type is 'NodePort'
##
nodePort: 30090
## Loadbalancer IP
## Only use if service.type is "LoadBalancer"
loadBalancerIP: ""
loadBalancerSourceRanges: []
## Denotes if this Service desires to route external traffic to node-local or cluster-wide endpoints
##
externalTrafficPolicy: Cluster
## Service type
##
type: NodePort
...
grafana:
## Passed to grafana subchart and used by servicemonitor below
##
service:
portName: http-web
nodePort: 30080
type: NodePort
...
alertmanager:
## Deploy alertmanager
##
enabled: true
...
## Configuration for Alertmanager service
##
service:
annotations: {}
labels: {}
clusterIP: ""
## Port for Alertmanager Service to listen on
##
port: 9093
## To be used with a proxy extraContainer port
##
targetPort: 9093
## Port to expose on each node
## Only used if service.type is 'NodePort'
##
nodePort: 30903
## List of IP addresses at which the Prometheus server service is available
## Ref: https://kubernetes.io/docs/user-guide/services/#external-ips
##
...
## Service type
##
type: NodePort
修改了
prometheusSpec.serviceMonitorSelectorNilUsesHelmValues设置为false
prometheusSpec.serviceMonitorSelectorNilUsesHelmValues 设置为 false# If true, a nil or {} value for prometheus.prometheusSpec.serviceMonitorSelector will cause the
# prometheus resource to be created with selectors based on values in the helm deployment,
# which will also match the servicemonitors created
#
serviceMonitorSelectorNilUsesHelmValues: false
在
configMap配置additionalScrapeConfigs添加gpu-metrics:
configMap 配置 additionalScrapeConfigs 添加 gpu-metrics# AdditionalScrapeConfigs allows specifying additional Prometheus scrape configurations. Scrape configurations
# are appended to the configurations generated by the Prometheus Operator. Job configurations must have the form
# as specified in the official Prometheus documentation:
# https://prometheus.io/docs/prometheus/latest/configuration/configuration/#scrape_config. As scrape configs are
# appended, the user is responsible to make sure it is valid. Note that using this feature may expose the possibility
# to break upgrades of Prometheus. It is advised to review Prometheus release notes to ensure that no incompatible
# scrape configs are going to break Prometheus after the upgrade.
#
# The scrape configuration example below will find master nodes, provided they have the name .*mst.*, relabel the
# port to 2379 and allow etcd scraping provided it is running on all Kubernetes master nodes
#
additionalScrapeConfigs:
- job_name: gpu-metrics
scrape_interval: 1s
metrics_path: /metrics
scheme: http
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- gpu-operator
relabel_configs:
- source_labels: [__meta_kubernetes_pod_node_name]
action: replace
target_label: kubernetes_node
最后执行部署,部署中采用自己定制的values:
kube-prometheus-stackhelm install prometheus-community/kube-prometheus-stack \
--create-namespace --namespace prometheus \
--generate-name \
--values /tmp/kube-prometheus-stack.values
备注
上述手工编辑替换的方法比较繁琐,实际上 helm 支持命令行直接替换变量参数:
kube-prometheus-stackhelm install prometheus-community/kube-prometheus-stack \
--create-namespace --namespace prometheus \
--generate-name \
--set prometheus.service.type=NodePort \
--set prometheus.prometheusSpec.serviceMonitorSelectorNilUsesHelmValues=false
备注
实际上我已经完成了 使用Helm 3在Kubernetes集群部署Prometheus和Grafana ,而且我也是将 Prometheus监控 的服务端口映射为 NodePort (安装后手动修订部署),所以不再需要执行官方文档安装
不过,我在 在Kubernetes集群(z-k8s)部署集成GPU监控的Prometheus和Grafana 采用了NVIDIA的部署方案,请参考那次实践。
(可选方法)独立安装 NVIDIA DCGM (Data Center GPU Manager) 和 DCGM-Exporter
Prometheus + Grafana 监控 NVIDIA GPU 采用了另外一种直接在物理主机部署 NVIDIA DCGM (Data Center GPU Manager) 和 DCGM-Exporter 的方法,也就是直接采用 Systemd进程管理器 来运行这两个程序。
DCGM-Exporter 在GitHub官方介绍了通过 Docker 来运行 dcgm-exporter 的方法。
备注
对比之下,我感觉采用NVIDIA官方的手册更符合最新的部署模式,所以我在NVIDIA官方部署方式上进行一些调整
部署DCGM
备注
需要部署 dcgm-exporter 就可以,物理主机上无需再安装 NVIDIA DCGM (Data Center GPU Manager)
我在 dcgm-exporter 容器内部检查,容器内部已经安装了 nvidia-dcgm ,只不过似乎没有以服务方式运行。参考 Monitor Your Computing System with Prometheus, Grafana, Alertmanager, and Nvidia DCGM
# nv-hostengine
Started host engine version 2.4.6 using port number: 5555
# dcgmi discovery -l
1 GPU found.
+--------+----------------------------------------------------------------------+
| GPU ID | Device Information |
+--------+----------------------------------------------------------------------+
| 0 | Name: NVIDIA Graphics Device |
| | PCI Bus ID: 00000000:09:00.0 |
| | Device UUID: GPU-794d1de5-b8c7-9b49-6fe3-f96f8fd98a19 |
+--------+----------------------------------------------------------------------+
0 NvSwitches found.
+-----------+
| Switch ID |
+-----------+
+-----------+
注意,容器内部必须先启动 nv-hostengine 才能运行 dcgmi discovery -l 检查主机的GPU卡
在容器内部可以执行 curl localhost:9400/metrics 获得GPU的 metrics数据
添加
dcgm-exporterhelm repo:
helm repo add gpu-helm-charts \
https://nvidia.github.io/dcgm-exporter/helm-charts
helm repo update
安装
dcgm-exporterchart:
这里可能会遇到报错,原因是 dcgm-exporter 要求 Kubernetes >= 1.19.0-0 :
dcgm-exporter )Error: INSTALLATION FAILED: chart requires kubeVersion: >= 1.19.0-0 which is incompatible with Kubernetes v1.18.10
则采用 helm安装特定版本chart 方法完成低版本安装:
安装指定 2.6.10 版本 dcgm-exporter chart:
helm install --generate-name gpu-helm-charts/dcgm-exporter --version 2.6.10
安装成功的输出信息:
NAME: dcgm-exporter-1680364448
LAST DEPLOYED: Sat Apr 1 23:54:13 2023
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
1. Get the application URL by running these commands:
export POD_NAME=$(kubectl get pods -n default -l "app.kubernetes.io/name=dcgm-exporter,app.kubernetes.io/instance=dcgm-exporter-1680364448" -o jsonpath="{.items[0].metadata.name}")
kubectl -n default port-forward $POD_NAME 8080:9400 &
echo "Visit http://127.0.0.1:8080/metrics to use your application"
third-party Profiling module 错误
我在生产环境的依次一次部署中,先部署了 DCGM-Exporter (系统已经安装了 nvidia-device-plugin ,但是还没有部署 prometheus-stack ),非常奇怪, dcgm-exporter 的pod不断crash:
# kubectl -n nvidia-gpu get pods
NAME READY STATUS RESTARTS AGE
dcgm-exporter-1680885308-2ttq6 0/1 CrashLoopBackOff 241 20h
dcgm-exporter-1680885308-5rzsf 0/1 CrashLoopBackOff 0 20h
dcgm-exporter-1680885308-5w29s 0/1 CrashLoopBackOff 241 20h
dcgm-exporter-1680885308-68sv7 0/1 CrashLoopBackOff 0 119m
...
检查 kubelet 日志显示仅显示容器不断 CrashLoopBackOff
...
E0408 18:51:25.676318 41268 pod_workers.go:191] Error syncing pod 4c56555f-1b97-4d68-965b-af67cd99df48 ("dcgm-exporter-1680885308-68sv7_nvidia-gpu(4c56555f-1b97-4d68-965b-af67cd99df48)"), skipping: failed to "StartContainer" for "exporter" with CrashLoopBackOff: "back-off 1m20s restarting failed container=exporter pod=dcgm-exporter-1680885308-68sv7_nvidia-gpu(4c56555f-1b97-4d68-965b-af67cd99df48)"
...
此时检查pod日志,显示第三方profiling模块返回错误导致:
# kubectl logs dcgm-exporter-1680885308-68sv7 -n nvidia-gpu
time="2023-04-08T10:50:50Z" level=info msg="Starting dcgm-exporter"
time="2023-04-08T10:50:50Z" level=info msg="DCGM successfully initialized!"
time="2023-04-08T10:50:51Z" level=info msg="Collecting DCP Metrics"
time="2023-04-08T10:50:51Z" level=info msg="No configmap data specified, falling back to metric file /etc/dcgm-exporter/dcp-metrics-included.csv"
time="2023-04-08T10:50:53Z" level=fatal msg="Error watching fields: The third-party Profiling module returned an unrecoverable error"
在一个韩文 GPU Operator on CentOS 提示解决方法是: GPU Operator v1.3.0 升级到 v1.4.0
不过,同样操作系统和硬件( NVIDIA A100 Tensor Core GPU ) 以及驱动 ( Driver Version: 470.103.01 CUDA Version: 11.4 ),我之前部署的集群却没有问题。
备注
这个错误故障后来解决: 原因是阿里云租用的服务器部署Kubernetes,已经购买使用了阿里云的基于 prometheus-stack 魔改的监控,所以系统中有了一个 Systemd进程管理器 模式运行的 DCGM-Exporter 。但是阿里云把 dcgm-exporter 的运行名改成了 starship ,导致没有注意到物理主机上已经运行了相同的程序。由于 starship 和我部署的 dcgm-exporter DaemonSet 都是定时采集,很容易同时采集数据造成冲突。
备注
Kubernetes官方有一篇和NVIDIA合作的技术文档 Third Party Device Metrics Reaches GA 详细解析了NVIDIA GPU metrics采集的方案,我后续在 Kubernetes第三方设备metrics 汇总研究
配置 Grafana
共享Grafana dashboards 中有NVIDIA公司提供的一个专用dashboard NVIDIA DCGM Exporter Dashboard ,将该面板的JSON文件对应 URL https://grafana.com/grafana/dashboards/12239 添加:
选择菜单
Dashboards >> Import(没有成功)将
https://grafana.com/grafana/dashboards/12239直接填写到Import via grafana.com栏,然后点击Load或者(我实际采用此方法)先从 共享Grafana dashboards 下载
https://grafana.com/grafana/dashboards/12239对应的JSON文件,然后点击Load,此时会提示信息如下
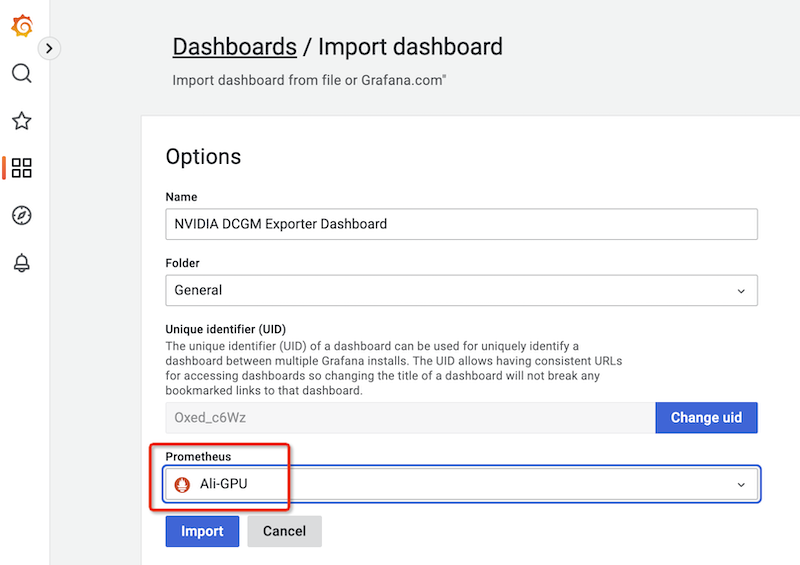
配置prometheus
此时虽然配置了Grafana,但是还拿不到 dcgm-exporter 数据,原因是 prometheus 尚未配置抓取数据(针对 9400 端口)
在 prometheus 的配置文件中添加 scrape_config 配置(具体参考 prometheus_configuration_scrape_config ),采用 更新Kubernetes集群的Prometheus配置 :
helm 支持 upgrade 指令,可以更新原先的 helm chart,也就说,可以在后面重新更新一些配置来添加Prometheus部署后的更新配置(比直接修订 prometheus.yml 方便)
备注
我最终采用 更新Kubernetes集群的Prometheus配置 方式,将NVIDIA官方文档的 configMap 配置 additionalScrapeConfigs 添加 gpu-metrics 整合成功。这样就能够初步显示出GPU的监控
输出
kube-prometheus-stack参数配置:
helm inspect values 输出Prometheus Stack的chart变量值helm inspect values prometheus-community/kube-prometheus-stack > kube-prometheus-stack.values
修改
/tmp/kube-prometheus-stack.values的configMap配置additionalScrapeConfigs添加gpu-metrics:
configMap 配置 additionalScrapeConfigs 添加 gpu-metrics (namespace由于部署原因设为default)# AdditionalScrapeConfigs allows specifying additional Prometheus scrape configurations. Scrape configurations
# are appended to the configurations generated by the Prometheus Operator. Job configurations must have the form
# as specified in the official Prometheus documentation:
# https://prometheus.io/docs/prometheus/latest/configuration/configuration/#scrape_config. As scrape configs are
# appended, the user is responsible to make sure it is valid. Note that using this feature may expose the possibility
# to break upgrades of Prometheus. It is advised to review Prometheus release notes to ensure that no incompatible
# scrape configs are going to break Prometheus after the upgrade.
#
# The scrape configuration example below will find master nodes, provided they have the name .*mst.*, relabel the
# port to 2379 and allow etcd scraping provided it is running on all Kubernetes master nodes
#
additionalScrapeConfigs:
- job_name: gpu-metrics
scrape_interval: 1s
metrics_path: /metrics
scheme: http
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- default
relabel_configs:
- source_labels: [__meta_kubernetes_pod_node_name]
action: replace
target_label: kubernetes_node
更新:
helm upgrade prometheus-community/kube-prometheus-stackhelm upgrade kube-prometheus-stack-1681228346 prometheus-community/kube-prometheus-stack \
--namespace prometheus --values kube-prometheus-stack.values
完成上述 helm upgrade 之后,就会在NVIDIA GPU Grafana Dashboard看到监控数据采集成功,显示类似如下:
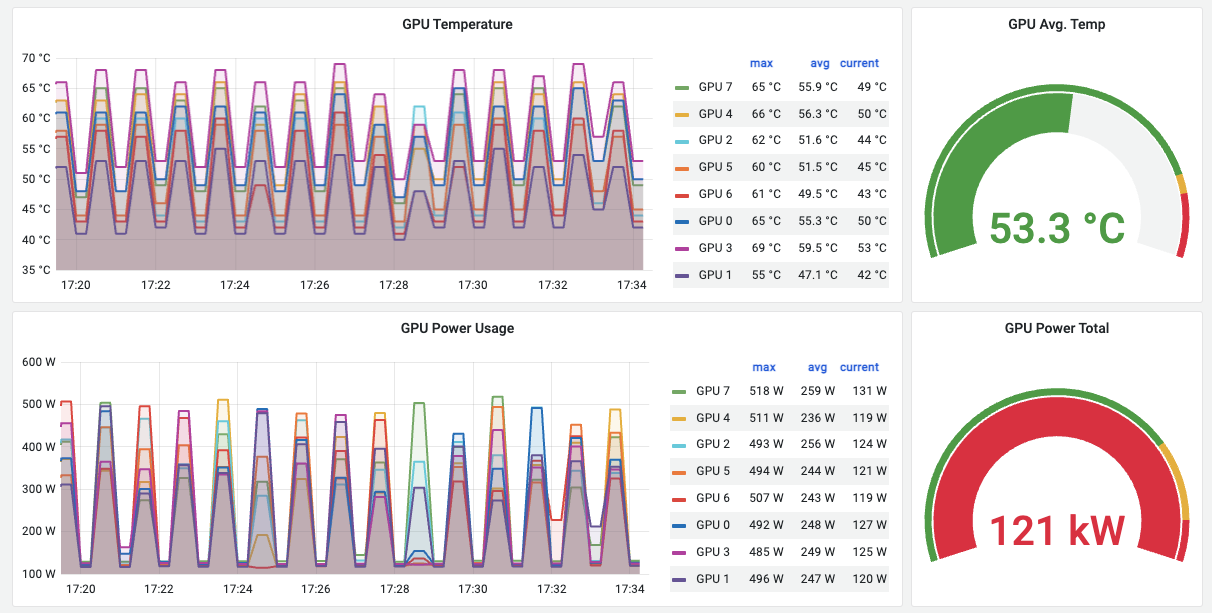
通过 dcgm-exporter 采集NVIDIA GPU监控数据: 温度和功率
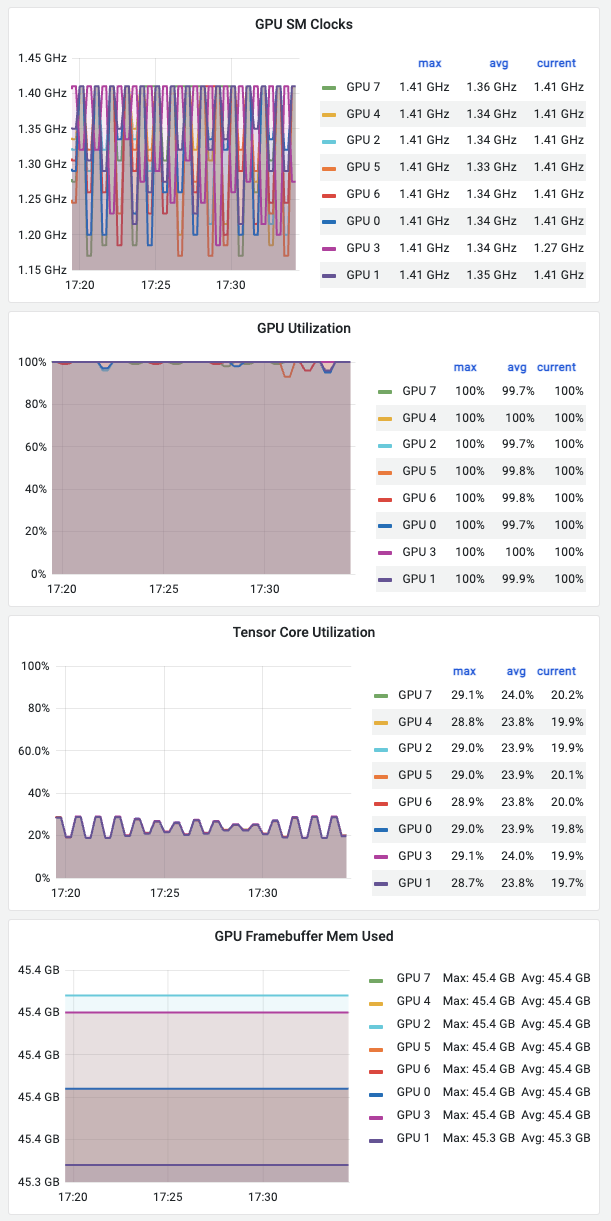
通过 dcgm-exporter 采集NVIDIA GPU监控数据: GPU时钟频率、GPU使用率、Tensor Core使用率、Framebuffer内存使用量
参考
Prometheus + Grafana 监控 NVIDIA GPU yaoge123 在 共享Grafana dashboards 提供了一个基于 DCGM-Exporter 数据采集的Grafana面板 GPU Nodes v2 ,比NVIDIA官方提供的面板 NVIDIA DCGM Exporter Dashboard 更多信息,不过我结合本文实践没有实现数据展示,需要再仔细研究研究。