Kubernetes调度器
在 Kubernetes概览 已经初步介绍了Kubernetes组件的关系,其中提到了Kubernetes Scheduler调度器工作原理:调度器通过Kubernetes的监视(Watch)机制来发现Controller Manager新创建的但是尚未调度到Node上的Pod。调度器会将发现的每一个未调度的Pod调度到合适的Node上运行。
kube-scheduler
kube-scheduler是Kubernetes集群默认调度器。如果有需求,Kubernetes设计是可以允许自己写一个调度组件并替换原有的kube-scheculer。
在一个集群中,所有满足Pod调度的节点(Node)被称为 可调度节点 。如果没有任何一个节点满足Pod的资源请求,那么这个Pod将一直停留在Pending(未调度)状态直到直到能够找到合适的节点。
调度器会在集群中找到一个Pod的所有可调度节点,然后通过一系列函数对这些可调度节点打分,选出最高得分的节点来运行Pod。然后调度器会将这个调度决定通知给kube-apiserver,整个过程称为绑定(binding)。
调度据测的考虑因素有:
单独和整体的资源要求
硬件/软件/策略限制
亲和以及反亲和要求 将Pod分配给节点
数据局限性(data locality)
负载间的干扰
等等
kube-
为什么调度系统不支持横向扩展架构
你可能会注意到几乎所有的集群调度系统都不支持横向扩展(scale out):例如,Hadoop MRv1早期是单一节点,集群最大规模是5000台主机。在YARN资源管理集群,依然有2个调度器,但是只有主调度器工作,另一个是备份,则最大管理服务器规模是10000台。在Mosos中通过优化,一个集群最大可以管理80000台。在Kubernetes 1.13则最大管理集群节点是5000台。
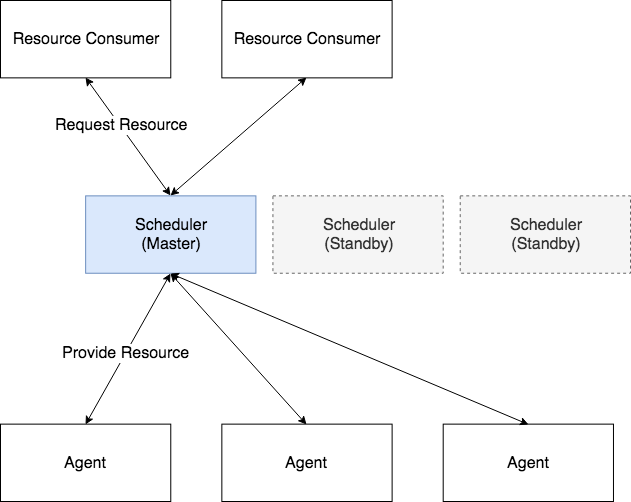
这是因为集群调度系统不能扩展导致的,要管理更多服务器只有创建多个集群。
为什么在Kubernetes集群中,即使部署了多个scheduler(通常我们会部署3个),但也只有一个scheduler是真正工作状态?常见的Internet应用程序通常都使用某种分布式技术来横向扩展,以便实现更大规模。
对于电子商务系统,很容易实现scale-out的横向扩展架构:
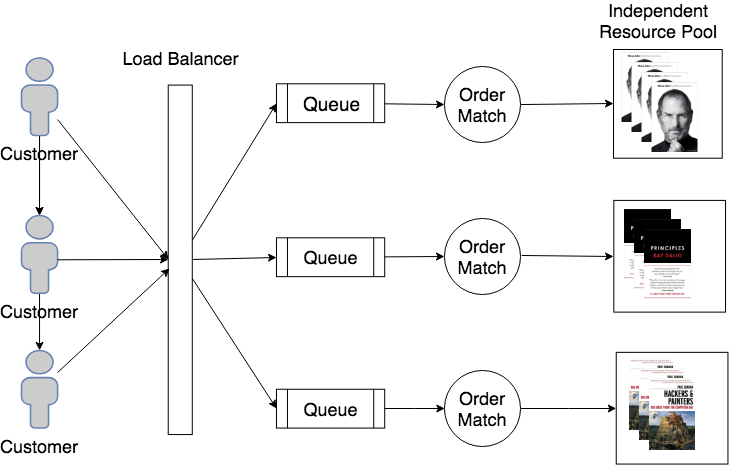
这是因为进入订单可以负载均衡放置到队列中(注意,这个队列是一个概念,实际上可以由消息队列程序构建,也可以由关系型数据库锁实现),由后端的订单处理进行匹配后就能从无依赖资源池取出处理。
请注意,在电商系统中,每个商品就是一个完全独立的资源池,购买「乔布斯传」和购买「黑客与画家」的订单系统是完全独立的(相互无依赖也不干扰)。
集群调度系统"无依赖资源池"只有一个
回到集群调度系统,就会看到,每个服务器节点就是一个资源,当自全请求发来时候,是需要将整个集群视为一个完整的集群资源池来使用,也就是不能分割:
调度系统需要全局检查整个集群资源来找到最优匹配资源服务器
对于多个调度器系统,则需要同步整个集群资源池的变化
这个设计就导致类似Oracle RAC系统,即使创建了多个调度服务器,也必须使用共享的资源池索引信息库来实现同步,所以锁开销会非常大,也非常难以实现横向扩展。